
Occupancy Networks
Over the last decade, deep learning has revolutionized computer vision. Many vision tasks such as object detection, semantic segmentation, optical flow estimation and more can now be solved with unprecedented accuracy using deep neural networks.
As many of these problems are represented in the 2D image domain, powerful 2D convolutional neural network architectures can be leveraged. However, the physical world we live in is not two- but three-dimensional! Thus, reasoning in three dimensions is crucial for enabling intelligent systems to interact with their 3D environment. Consider robot navigation as an example: in order to navigate, a robot must reconstruct its environment in 3D and store this 3D representation in a data efficient manner. But what constitutes a good 3D representation which is easily accessible to deep neural networks? In our recent work Occupancy Networks - Learning 3D Reconstruction in Function Space, we examine this question and propose a novel output representation which allows to apply powerful deep architectures to the 3D domain.
The Challenge
Several 3D output representations have been proposed for learning-based 3D reconstruction. Voxels are a straightforward generalization of pixels to the 3D domain. They partition the 3D space into 3D cells according to an equidistant grid. The size of each voxel or grid cell determines the granularity of the representation. Unfortunately, voxels come with a severe limitation, in particular in the context of deep learning: while the memory requirements for 2D images grows quadratically with resolution, the memory requirements of voxels grow cubically with resolution. Consequently, if one would convert a state-of-the-art fully convolutional architecture for 2D images operating at a resolution of 5122 pixels into a 3D convolutional architecture operating on voxels, this network would require 512 GPUs to satisfy the memory requirements of the resulting network, now operating on 5123 voxels. In practice, most voxel-based architectures are therefore restricted to very low resolution such as 323 or 643 voxels, resulting in coarse “Manhattan world” reconstructions:

Another representation that has been investigated in the past are point clouds. However, while very flexible and computationally efficient, they lack connectivity information about the output and most existing architectures are limited in the number of points that can be reconstructed (typically a few thousands):

Other works have considered meshes comprising vertices and faces as output representation. Unfortunately, this representation either requires a template mesh from the target domain or sacrifices important properties of the 3D output such as connectivity. If a template mesh is used, the resulting model is restricted to a very specific domain such as faces or human bodies. It is very difficult to construct models that can handle multiple object categories such as chairs or cars at the same time. Approaches which sacrifice connectivity often result in non-smooth meshes with artifacts such as self-intersections:

Given the limitations of existing 3D output representations for deep learning, we asked ourselves: Can we find a 3D output representation for deep neural networks that
- can represent meshes of arbitrary topology and at arbitrary resolution,
- is not restricted to a Manhattan world,
- is not limited by excessive memory requirements,
- preserves connectivity information,
- is not restricted to a specific domain (e.g. object class), and
- blends well with deep learning techniques?
Interestingly, it is indeed possible to find a representation of 3D geometry which satisfies all of these requirements.
Our Approach
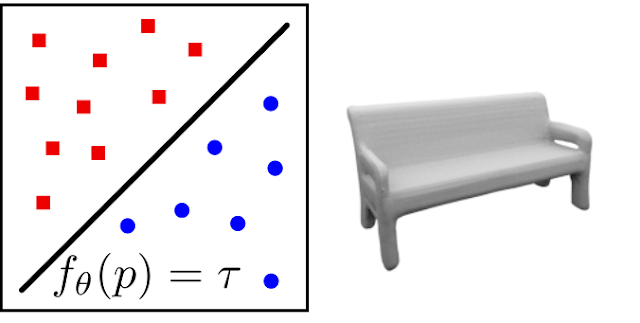
The solution is surprisingly simple: we represent the 3D geometry as the decision boundary of a classifier that learns to separate the object’s inside from its outside. This yields a continuous implicit surface representation that can be queried at any point in 3D space and from which watertight meshes can be extracted in a simple post-processing step. More formally, we learn a non-linear function
\[f_\theta: \mathbb R^3 \to [0, 1]\]that takes a 3D point as input and outputs its probability of occupancy. In our experiments, we represent this function using a deep neural network which we call Occupancy Network. The decision boundary (at $f_\theta(p)=0.5$) represents the surface of the reconstructed shape:


This simple idea solves all of the problems mentioned in the previous section: the implicit representation can represent meshes of arbitrary topology and geometry, is not restricted by memory requirements, preserves connectivity information and naturally blends with deep learning techniques. Additionally, the model can be conditioned on an observation such as an image. This enables it to solve tasks such as 3D reconstruction from a single image. We train our model with randomly sampled 3D points for which we know the true class label (inside or outside). For inference, we propose a simple algorithm which efficiently extracts meshes from our representation by incrementally constructing an octree.
Does it work?
We conducted extensive experiments on 3D reconstruction from point clouds, single images and voxel grids. We found that Occupancy Networks allow to represent fine details of 3D geometry, often leading to superior results compared to existing approaches.


Further Information
To learn more about Occupancy Networks, check out our video here:
You can find more information (including the paper and supplementary) on our project page. If you are interested in experimenting with our occupancy networks yourself, download the source code of our project and run the examples. We are happy to receive your feedback!
@inproceedings{Occupancy Networks,
title = {Occupancy Networks: Learning 3D Reconstruction in Function Space},
author = {Mescheder, Lars and Oechsle, Michael and Niemeyer, Michael and Nowozin, Sebastian and Geiger, Andreas},
booktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}



