
Animate Implicit Shapes with Forward Skinning
Neural implicit surface representation is a recently emerging representation of 3D shapes. They represent the occupancy or SDF field of the 3D shape with multi-layer perceptrons (MLP). These MLPs take a 3D coordinate as input and outputs the corresponding occupancy or SDF value. Such representations have several benefits, including topological flexibility, low memory footprint, and resolution independence, leading to impressive advances in modeling 3D rigid objects and scenes.
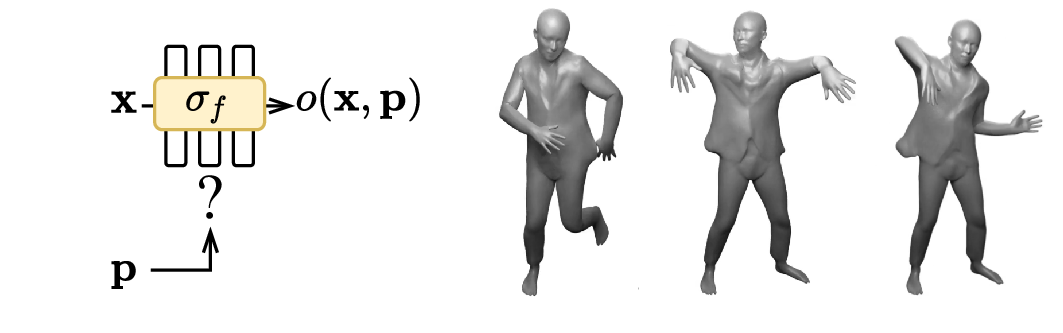
However, adapting them to non-rigidly moving objects, such as humans, is not straightforward. In this post, we will explain our approach to animating neural implicit surfaces.
Skinning Polygon Meshes
Let’s first take a look at how polygon meshes are animated. A very common approach is linear blend skinning (LBS). LBS requires a canonical template mesh to represent the surface and a set of handles (bones) to control the posture. Each vertex on the canonical mesh has skinning weights that define how bones influence this vertex. By taking the weighted average of given bone transformations, we know how each vertex should be transformed. The skinning weights are either defined by artists or can be learned from data.
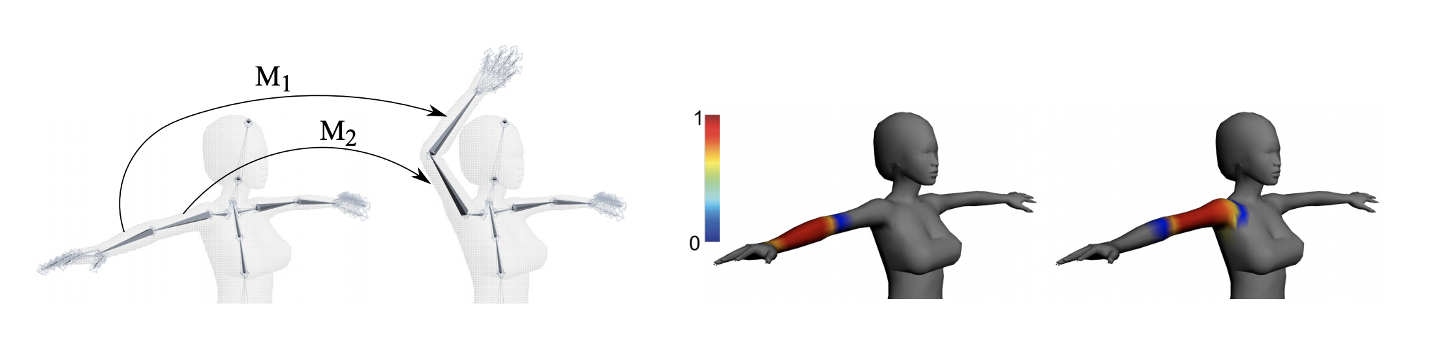 Credit: this image is taken from this tutorial by Ladislav Kavan.
Credit: this image is taken from this tutorial by Ladislav Kavan.
Despite being simple, LBS produces decent animation quality and has become a standard tool in the graphics pipeline. So, can we bring LBS to neural implicit surfaces?
Skinning Neural implicit Surfaces
Unlike meshes where the skinning weights are defined only on vertices, we now need the skinning weights for any point in space - a continuous skinning weights field. This field can be represented as an MLP, which maps 3D coordinates to skinning weights.
Now, in which space should this field be defined? In deformed space or canonical space?
Backward Skinning: Weights in Deformed Space
Previous work chooses to define the skinning weights in deformed space. To know whether a point in deformed space is occupied or not, we first query its skinning weights, compute the transformation of the point via LBS, and then we know the canonical correspondence of that point.
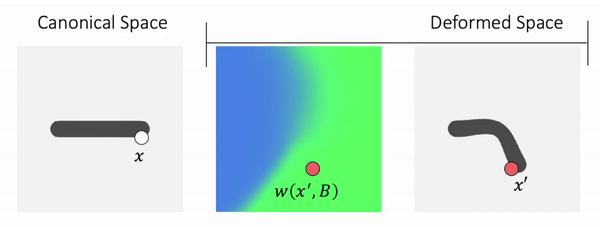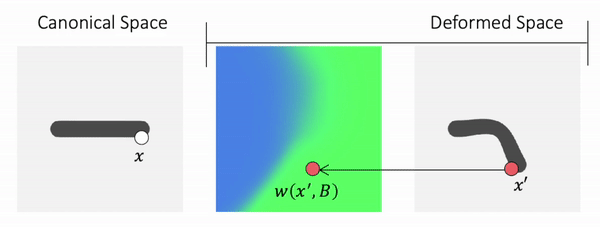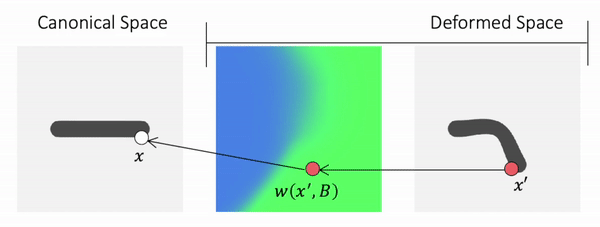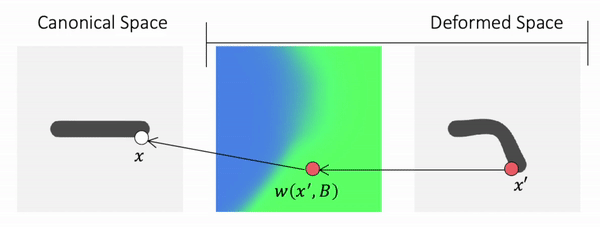
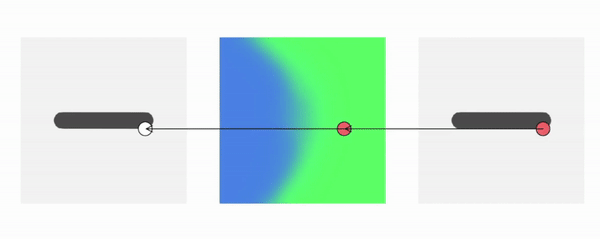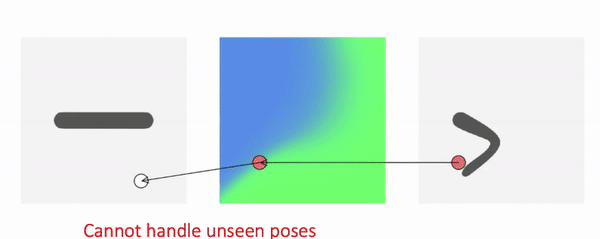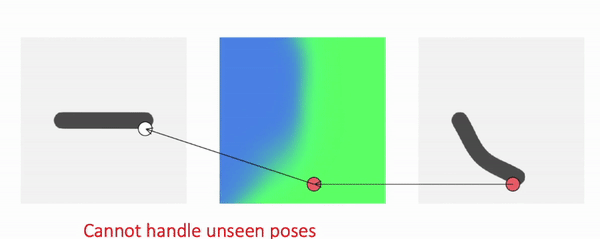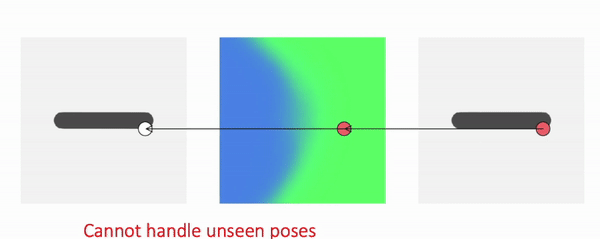
We call such method backward skinning as it maps points in deformed space back to canonical space. Note that in this formulation, we need to know the skinning weights of points in deformed space. In different poses, the same point in the deformed space will have different skinning weights, because the deformed space itself changes with the pose. So the MLP needs to memorize the skinning weights in different poses and cannot generalize to unseen poses, which is an important limitation.
Forward Skinning: Weights in Canonical Space
How about defining the skinning weights field in canonical space? We can then transform a point in canonical space to deformed space.
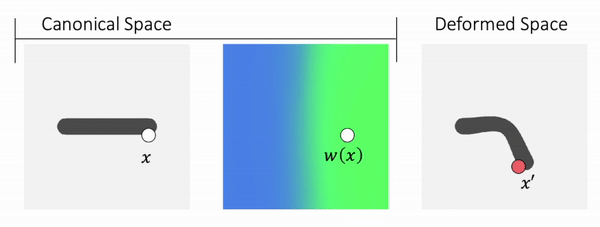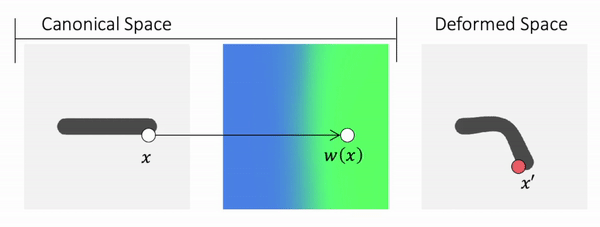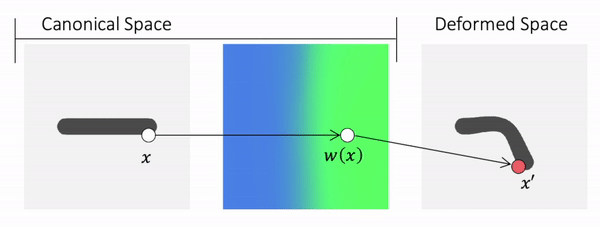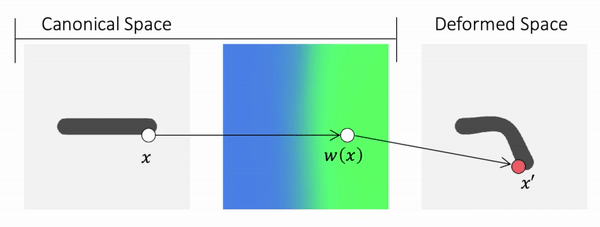
Because the skinning weights field is defined in the canonical space, it is independent of the pose and naturally does not suffer from generalization.
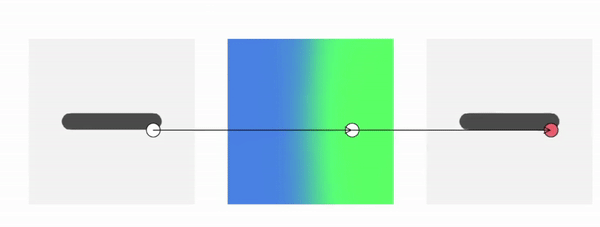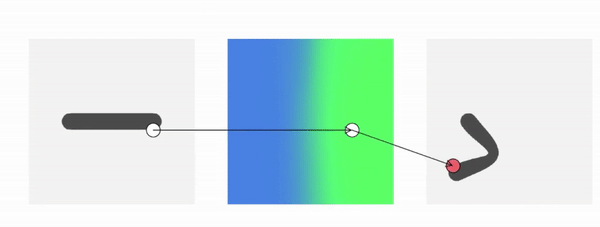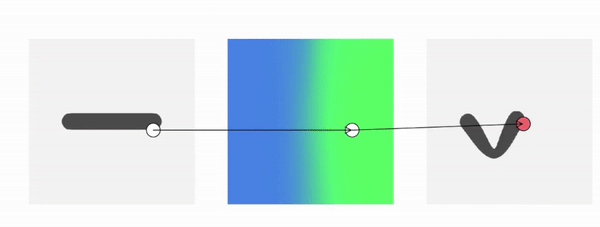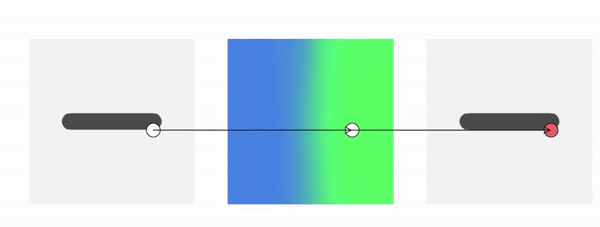
But why hasn’t forward skinning been used before? We often need to know the occupancy of a specific point in deformed space, which is not straightforward for forward skinning. We know where a given canonical point goes with forward skinning, but not where a given deformed point comes from.
Our approach addresses this technical challenge and enables querying canonical correspondences of deformed points with forward skinning weights. Using our approach, we can generate deformed shapes in any poses, even those unseen during training.
Our Approach
The core of the problem is: given a forward mapping function $d:x \rightarrow x’$, determine it’s inverse mapping $x’ \rightarrow x$. In our case, $d$ is the composition of LBS and an MLP, which is not invertible. Thus, we resort to numerical methods. We use Broyden’s method, an iterative root finding algorithm, to find $x$ that satisfies the condition $d(x)=x’$. The solution $x$ we find is the canonical correspondence of the given $x’$.
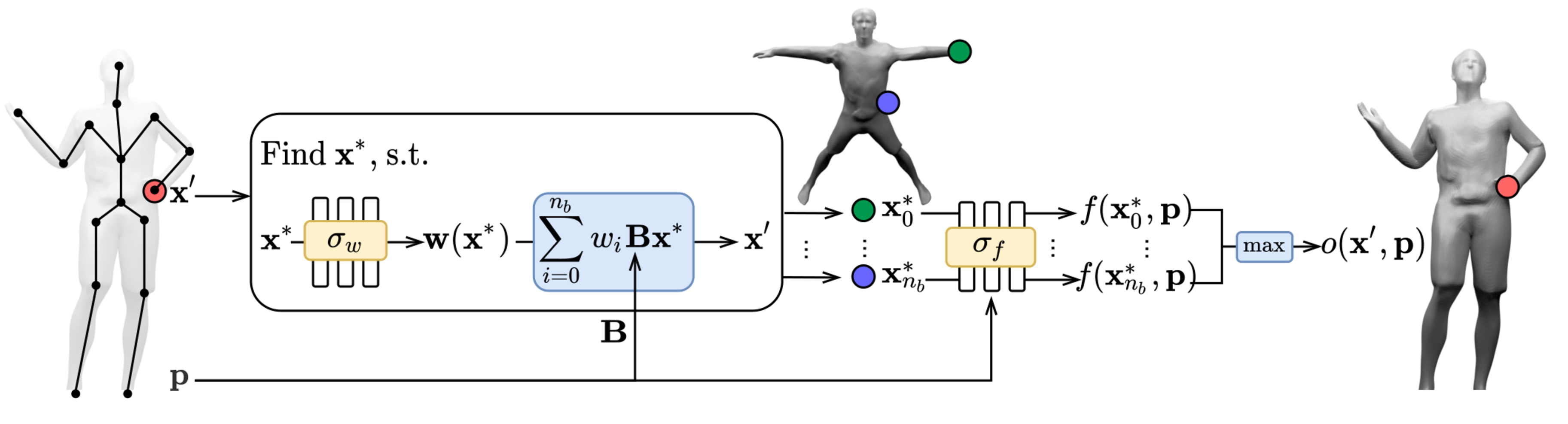
In many cases, one deformed point might have multiple canonical correspondences. For example, in the case above, the torso and hand points in canonical space move to the same location in deformed space. This means that the equation $d(x)=x’$ has multiple roots. To find all these roots, we initialize Broyden’s method from multiple initial states. These initial states are obtained by rigidly transforming the deformed point with individual bone transformations. After finding all canonical correspondences, we query their occupancy probabilities from the canonical shape network. We then aggregate these probabilities by taking their maximum - a standard operator for compositing multiple implicit shapes.
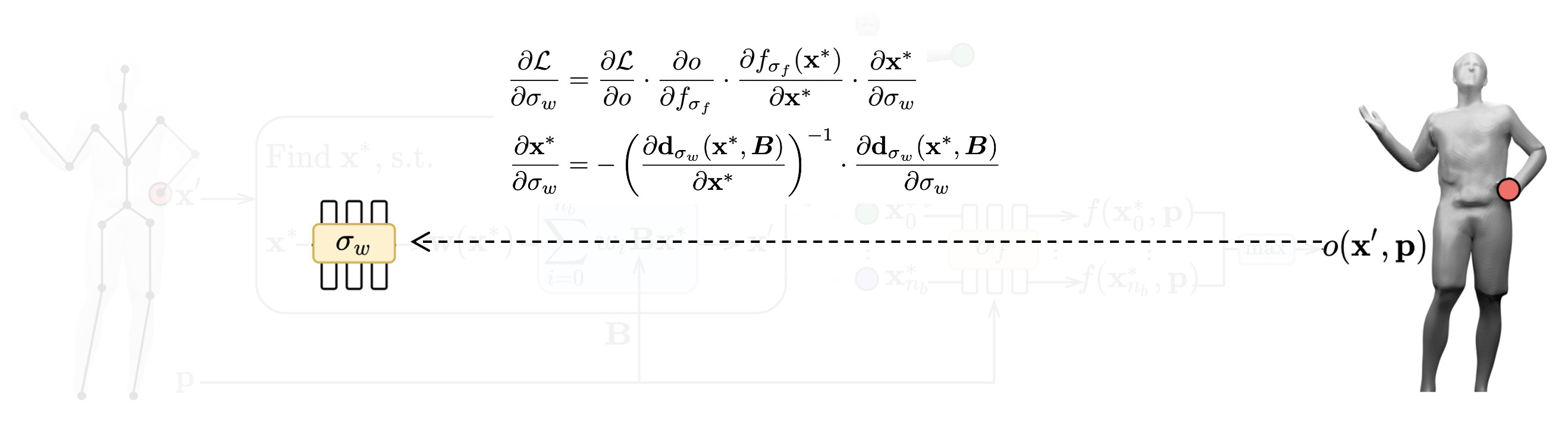
To this end, we obtain the occupancy probability of deformed points. We can then compare this to the ground-truth occupancy for training. However, the iterative root finding algorithm is not trivially differentiable for training. We could unroll the iterations and apply standard chain rules to compute gradients, but it would be highly time and memory-consuming. To address this problem, we derive the analytical gradients using the implicit differentiation theorem. This allows us to train our skinning weights and occupancy network from deformed observations using standard back-propagation.
Does it work?
We use our approach to model 3D minimally clothed humans. We train our method using meshes in various poses and ask the model to generate novel poses during inference time. Here is one example:
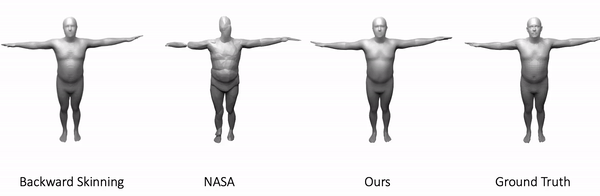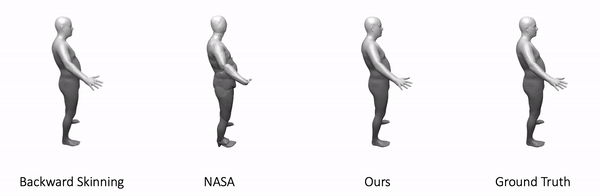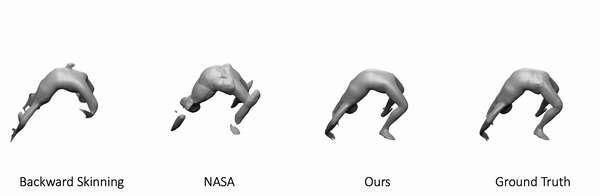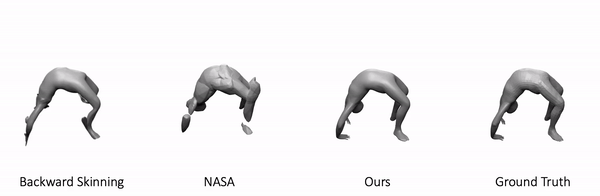
As shown, our method generalizes to these challenging and unseen poses. In comparison, backward skinning produces distorted shapes for unseen poses. The other baseline, NASA, models human body as a composition of multiple parts and suffers from discontinuous artifacts at joints.
Our method can also represent other objects, such as clothed humans and animal:
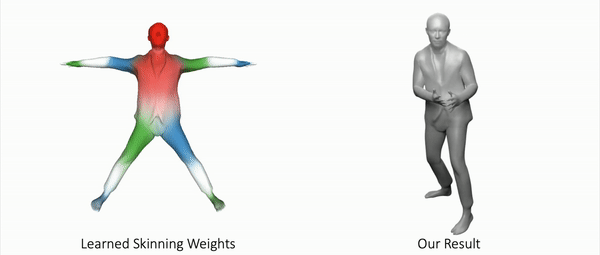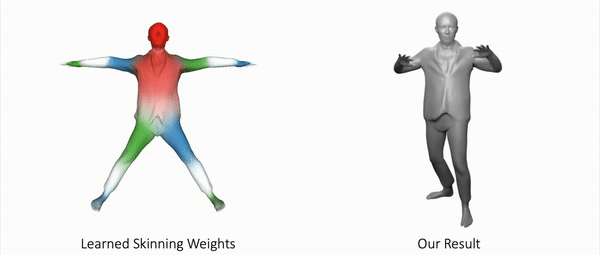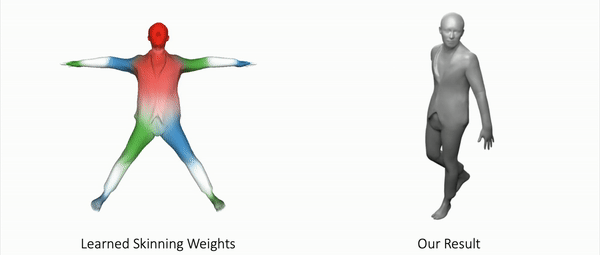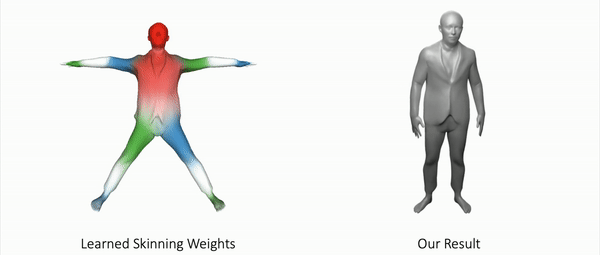
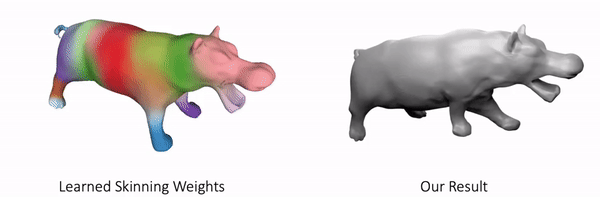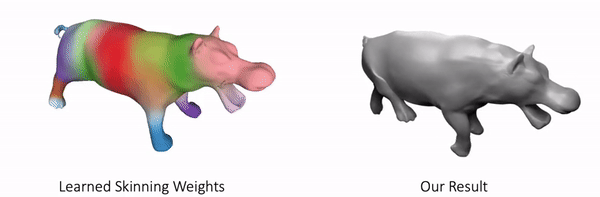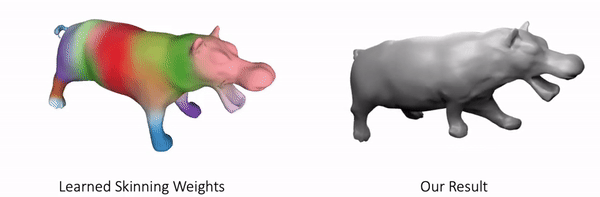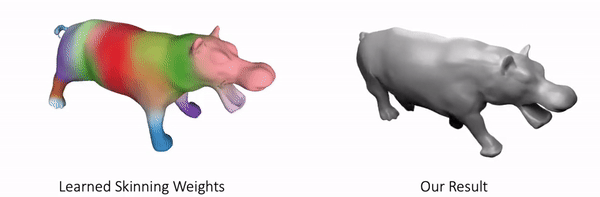
Further Information
Thank you for reading! We invite you to try out our code and to check out our paper/video/project page for more technical details. If you find our work helpful, please consider citing it as
@inproceedings{chen2021snarf,
title={SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes},
author={Chen, Xu and Zheng, Yufeng and Black, Michael J and Hilliges, Otmar and Geiger, Andreas},
booktitle={International Conference on Computer Vision (ICCV)},
year={2021}
}



