
On the Frequency Bias of Generative Models
Generative adversarial networks (GANs) have enabled photorealistic and high-resolution image synthesis. However, even for state-of-the-art methods, generated images are still straightforward to identify in the frequency domain. Compared to the real images, the average spectrum of the generated images looks quite different, particularly for high frequencies.
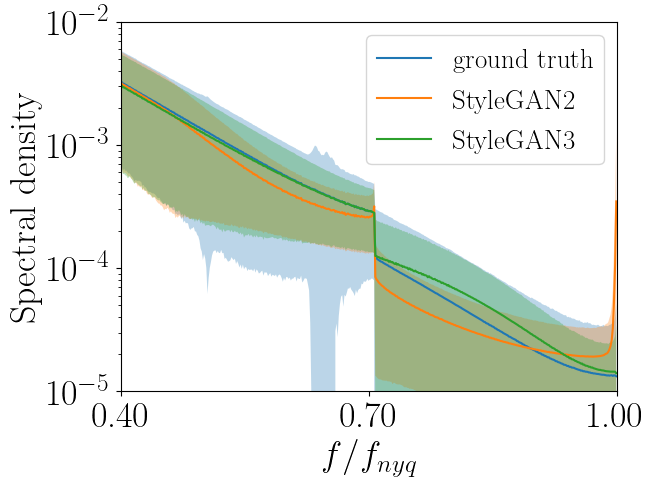
This is somewhat surprising because the key objective of GAN training is to make the statistics of the generated images similar to the statistics of the real images. More specifically, GANs are trained in an adversarial game of two players, a generator and a discriminator. The generator generates the images and the discriminator has to distinguish between real and generated images. Over the course of training, the generated images should become indistinguishable from the real images. Here it gets interesting: While the generated images indeed appear photorealistic, their spectrum gives away their identity. In fact, a very simple classifier on the spectrum can distinguish real and generated images almost perfectly. Does this mean that the discriminator, a deep neural network with millions of parameters, is blind to the spectral artifacts? Or is the generator not even able to generate images with the correct spectral statistics? One clue to answering these questions is that the spectral artifacts prevailingly occur at high frequencies. This indicates that low frequencies might be easier to generate or detect for neural networks. Hence, we ask
Is there a frequency bias in the generator and/or the discriminator?
This is a non-trivial question as GAN training involves two players where architectures for both the generator and discriminator, loss functions, as well as the dataset statistics can all affect the generated images. So let us first narrow down potential factors and consider generator and discriminator in isolated testbeds.
Is there a frequency bias in the Generator?
Most existing works suspect that the upsampling operations in the generator cause the spectral artifacts.
So let us first investigate the effect of upsampling on the spectrum using a simple reconstruction task.
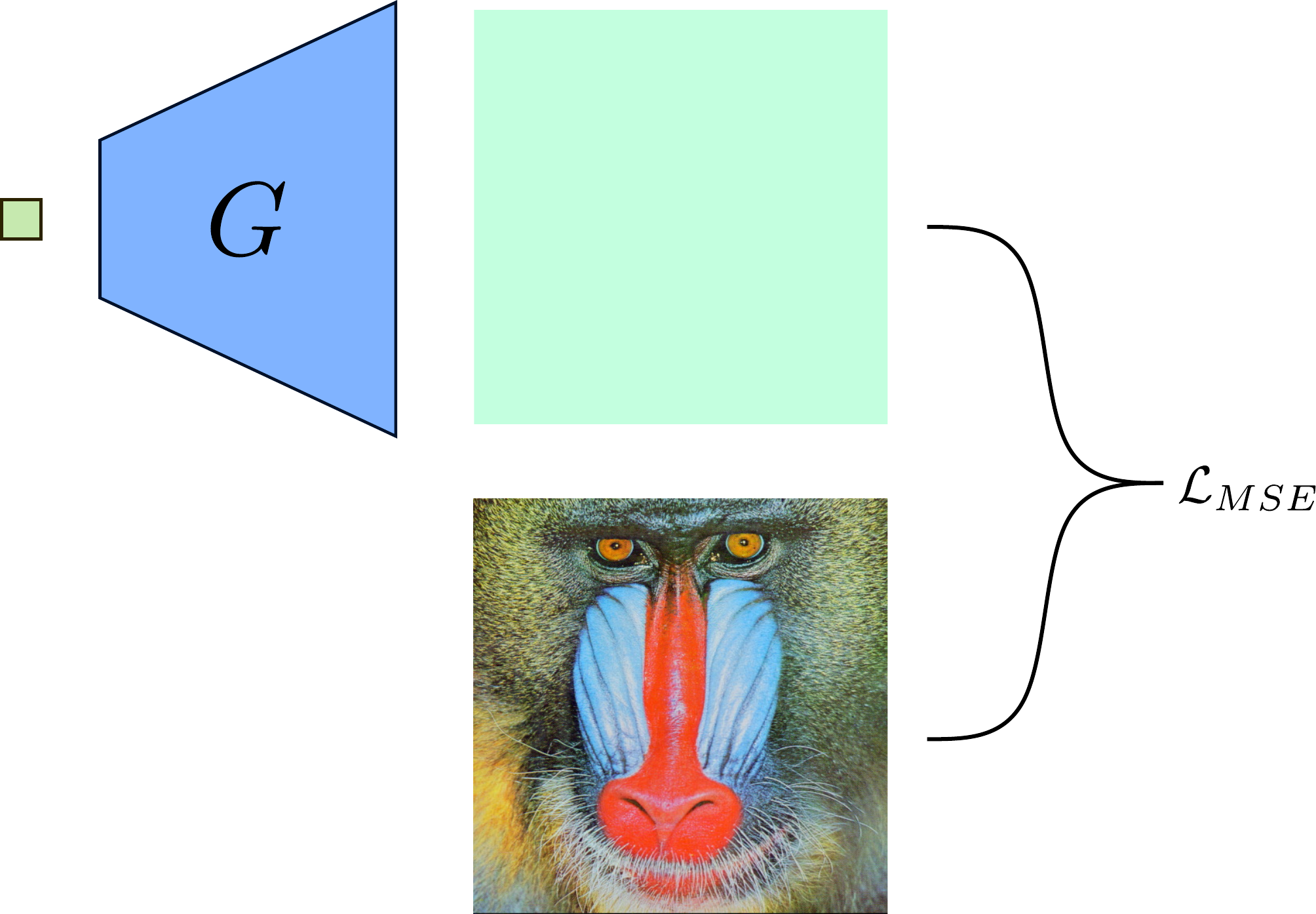
For a single image, the generator is given a fixed noise input from which it needs to reconstruct the image. To detect a frequency bias, we monitor the reconstructed image, the spectrum, and the error evolution of the spectrum over the course of training. The spectrum error evolution illustrates how the relative error between the ground truth and predicted reduced spectrum evolves during training. Red color indicates a higher predicted spectral density and blue color a lower predicted spectral density than in the training image.
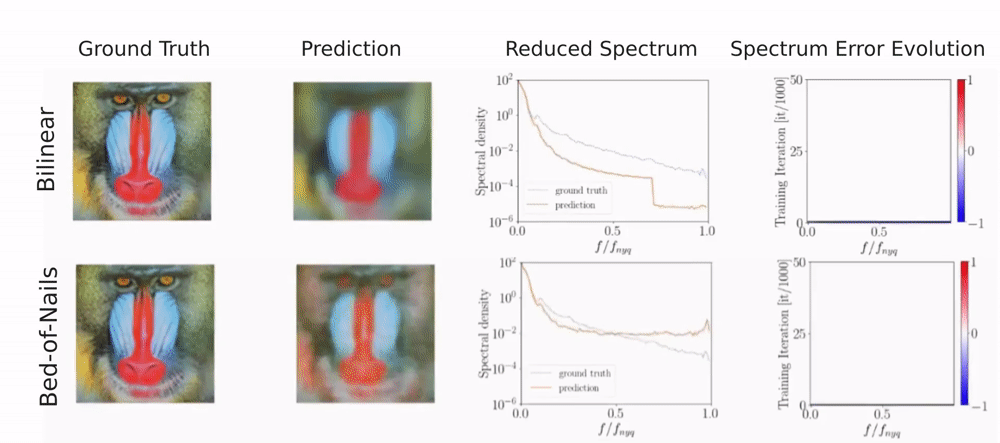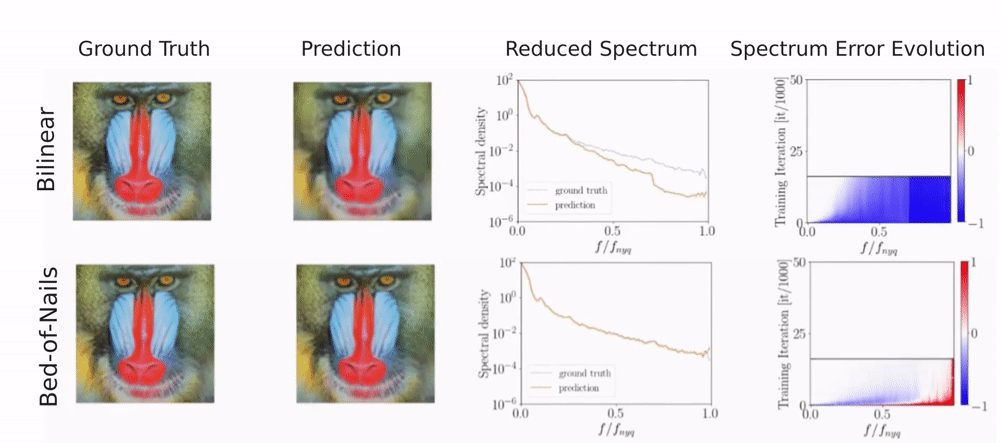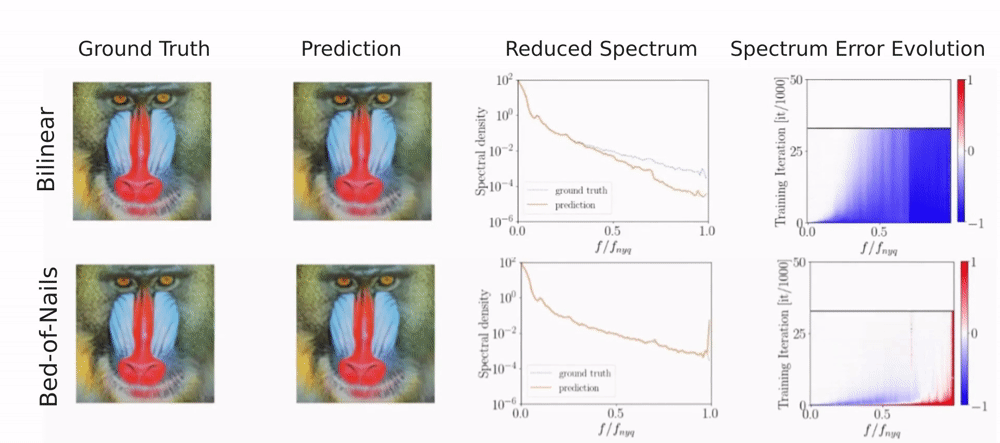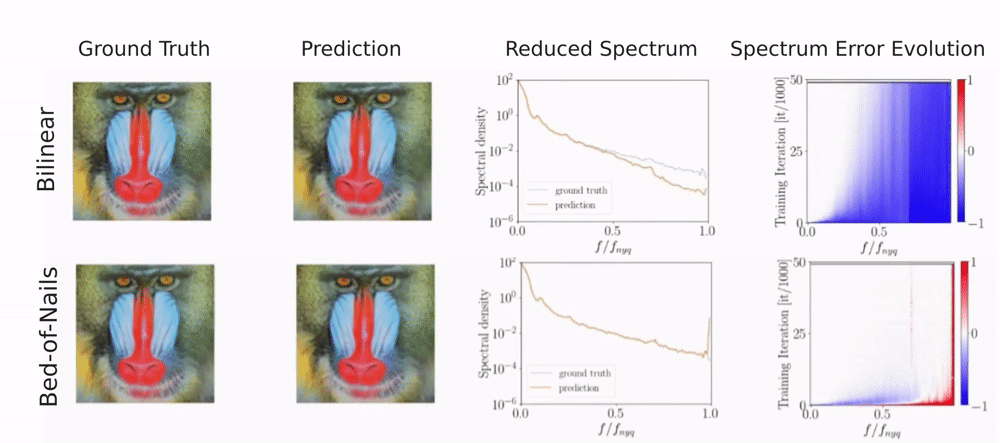
You can see that different upsampling methods bias the generator towards different spectral properties.
Due to its interpolation-based nature, bilinear upsampling results in overly smooth generated images.
This lack of high-frequency content shows in the reduced spectrum and, indicated by the blue color, in the spectrum error evolution.
With bed-of-nails upsampling the generator instead learns all frequencies approximately equally fast. However, there is a peak at the highest frequencies
which indicates checkerboard-like artifacts from inserting the zeros.
Follow-up question: Why do the learnable weights of the generator not compensate for the artifacts from upsampling?
Short answer: The mean-squared error used in our testbed penalizes small (absolute) errors less than large errors. Therefore, it penalizes checkerboard artifacts only slightly.
It turns out that when the loss function is sensitive to these artifacts the generator is indeed capable of compensating for them.
For more details please check out our paper.
This suggests that checkerboard patterns cannot explain the spectral artifacts alone and raises the question of whether the discriminator is able to detect high frequencies in the first place?
Is there a frequency bias in the Discriminator?
We investigate the spectral properties of the discriminator with a GAN-equivalent of a reconstruction task.
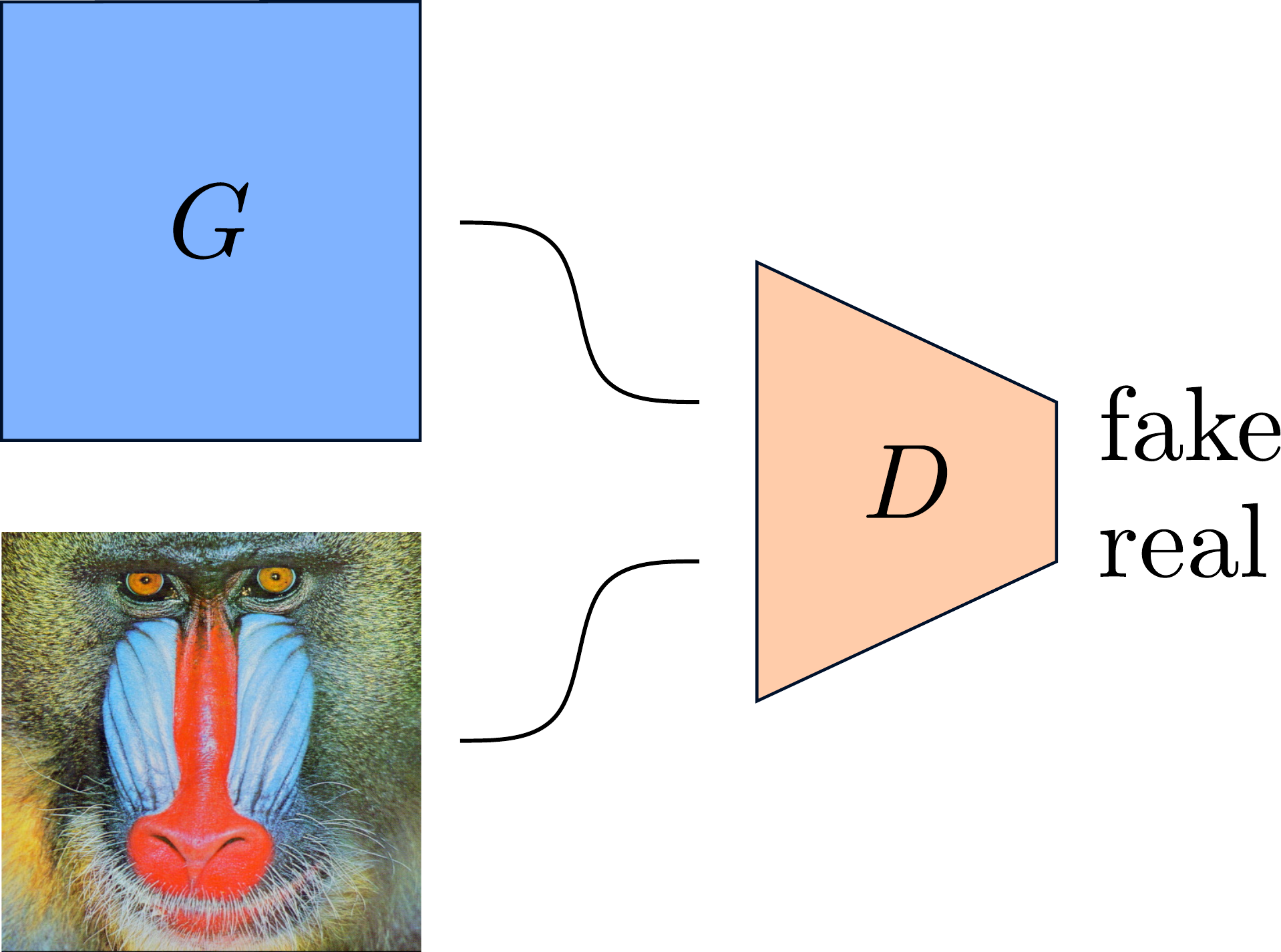 Specifically, we train a GAN but parameterize the generator as a learnable tensor with the same dimension as the input image.
This allows us to directly visualize the training signal provided by the discriminator.
As usual, the generator and discriminator are trained in an alternating fashion.
In addition to the original image, we consider a high-pass filtered version of the image to obtain a setting in which the high frequencies dominate the input signal.
Specifically, we train a GAN but parameterize the generator as a learnable tensor with the same dimension as the input image.
This allows us to directly visualize the training signal provided by the discriminator.
As usual, the generator and discriminator are trained in an alternating fashion.
In addition to the original image, we consider a high-pass filtered version of the image to obtain a setting in which the high frequencies dominate the input signal.
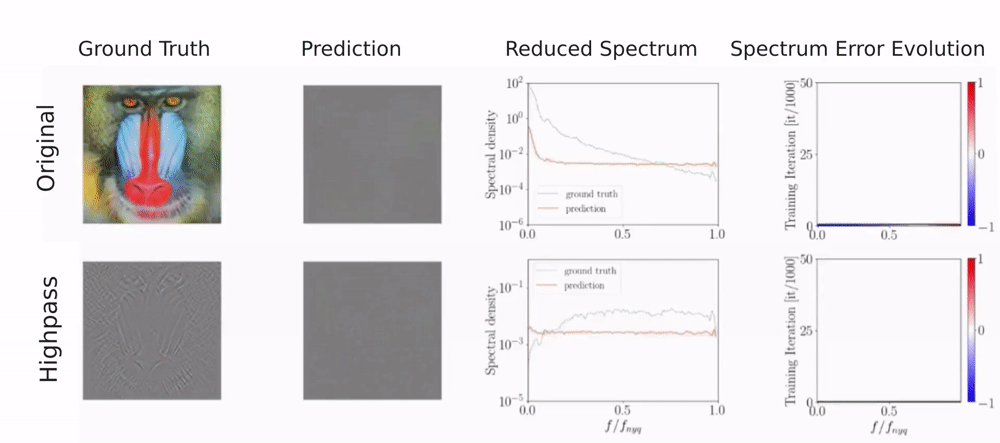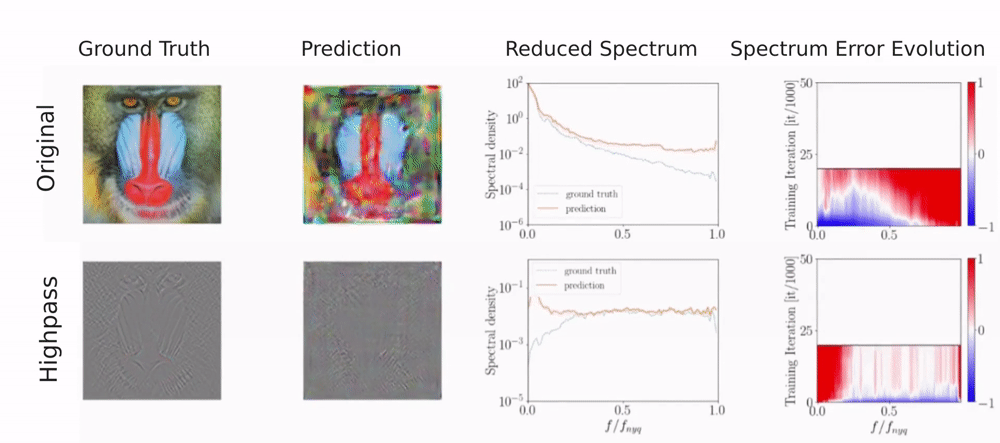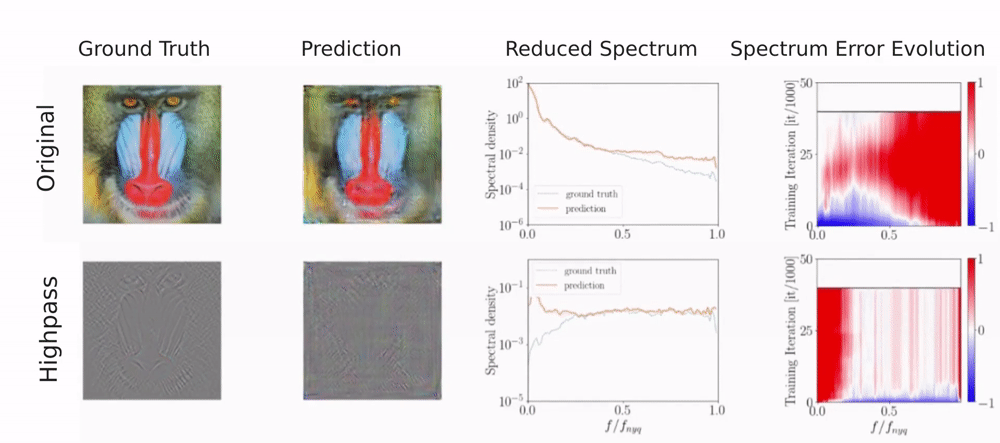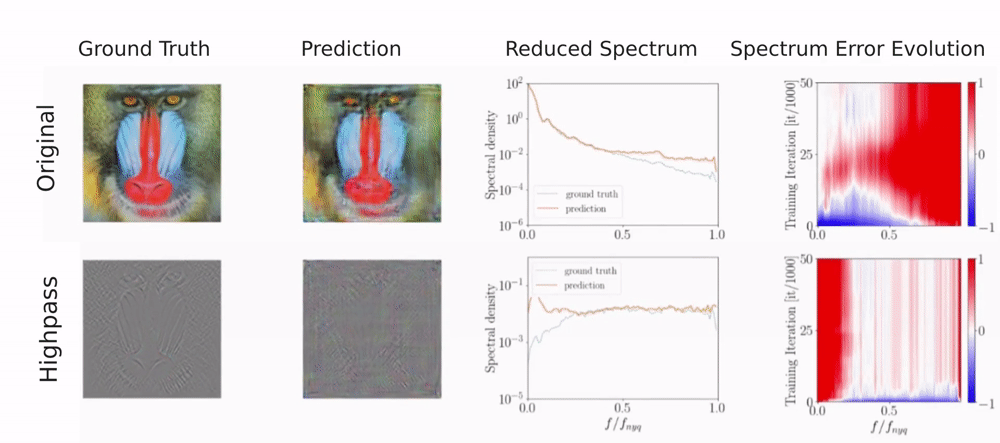
As you can see, the discriminator fits frequencies with high magnitudes well but struggles with frequencies of low magnitude. For the original image, low magnitudes correspond to high frequencies whereas for the high-pass filtered image low magnitudes correspond to low frequencies. This shows, that the discriminator does not struggle with high frequencies per se. Instead, it is sensitive to the magnitude of the frequencies. However, for natural images high frequencies typically have the lowest magnitudes, making them difficult to detect for the discriminator.
Follow-up question: Is aliasing a problem in the discriminator because it downsamples the images?
Short answer: Yes. The reconstructed image looks significantly worse than the reconstructed image from the generator testbed.
The artifacts in the reconstruction vanish when the convolutional discriminator is replaced with an MLP which uses no downsampling.
check out our paper if you want to learn more about different downsampling operations and their effects on the training signal.
So how do we fix this?
Recent works propose several measures to reduce the spectral artifacts in generated images. We found the most effective to be an additional discriminator on the reduced spectrum as proposed in Jung et al.. However, the discriminator is applied to the reduced (1D), and not the full (2D), spectrum and might therefore incentivize a shortcut solution. Indeed, we find that finetuning StyleGAN with this loss can introduce artifacts in the background of the generated images to fool the spectral discriminator.
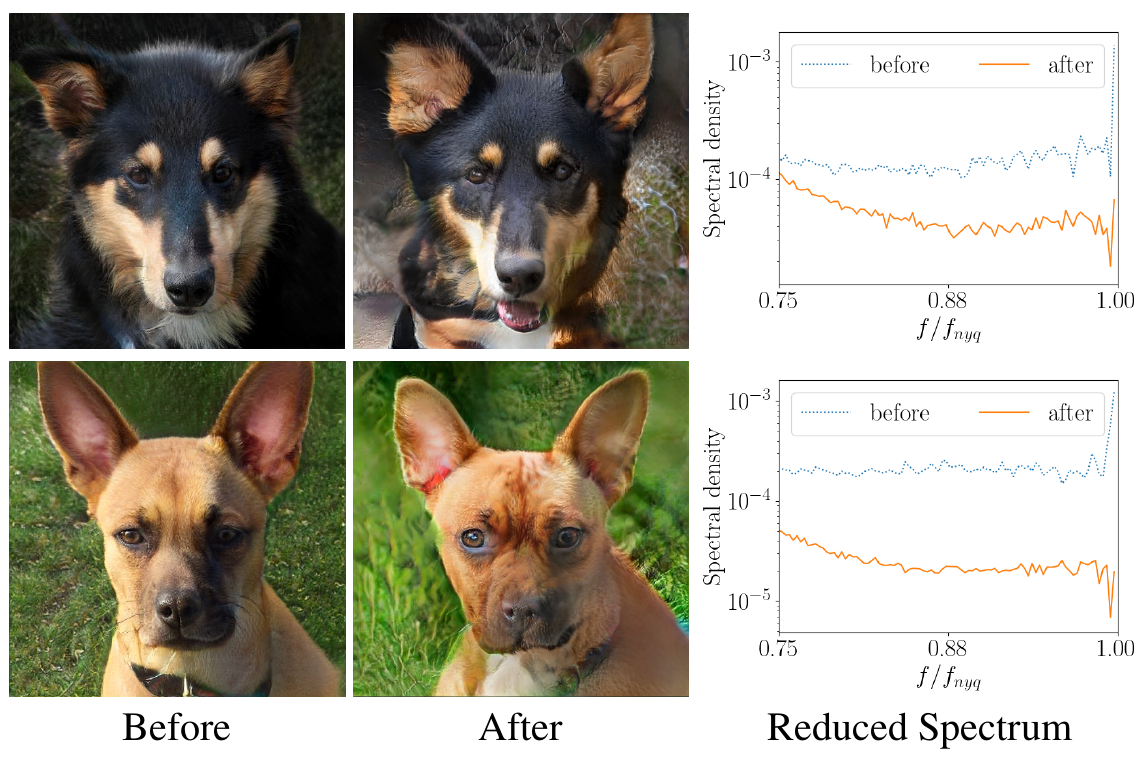
Conclusion: For now, artifacts in generated images remain an open problem. Our findings suggest that the design of the discriminator plays an important role and deserves more attention in future work. Interesting directions might be to explore alternative downsampling operations and to consider approaches that enable pixel-level supervision for the discriminator.
Curious?
Analyze your own GAN architecture or investigate potential fixes with our generator and discriminator testbeds. For more details on the topic, watch our NeurIPS’21 talk:
Further information (including the paper and supplementary) is available on our project page. If you are interested in experimenting with our testbeds, download the source code of our project and run the examples. We are happy to receive your feedback!
@inproceedings{Schwarz2021NEURIPS,
title = {On the Frequency Bias of Generative Models},
author = {Schwarz, Katja and Liao, Yiyi and Geiger, Andreas},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021},
doi = {}
}



