
Novel approaches for fast rendering of neural coordinate-based representations
Neural coordinate-based or implicit representations like the one used in Neural Radiance Fields (NeRF) offer very good compression but are due to their slow decoding speed inherently unsuited for real-time applications. In this blog post, I discuss several recent works that address this limitation of neural 3D representations.
The video above was directly rendered in real-time from the neural representation adopted by KiloNeRF.
Neural coordinate-based representations
Since their introduction (Chen et al., 2019, Mescheder et al., 2019, Park et al, 2019) to the computer vision community, neural coordinate-based representations for 3D scenes are being used in an ever-increasing number of works. Here the scene is encoded with help of a (deep) neural network that gets as input a 3D coordinate and gives out scene properties like color, occupancy or volumetric density at the given 3D coordinate. This leads to a highly compressed representation that can be directly learned from various kinds of supervision signals like multi-view images. NeRF demonstrated that high-quality results for novel view synthesis (NVS) can be achieved by making use of such a coordinate-based representation. A fascinating aspect is that a scene can be encoded with only 5 MB of memory and this holds even though NeRF models color in a view-dependent way, which means that the scene function is even 5-dimensional (3 dimensions for position and 2 dimensions for viewing direction). In contrast, storing a scene uncompressed, i.e. with a 5-dimensional table (view-dependent voxel grid), would consume tens of gigabytes of disk storage. However, the high compression ratio of NeRF and other neural representations comes with a steep price. Directly rendering such a representation, which typically requires dense evaluation of the neural network, is painfully slow and therefore these representations are unsuited for real-time applications. Recently, a lot of works tried to address this issue of coordinate-based neural representations and NeRF in particular.
KiloNeRF
For each point where we want to evaluate the NeRF a forward pass through a Multi-Layer Perceptron (MLP) is required. This means that we have to execute a sequence of expensive vector-matrix multiplications to decode each individual point. Naturally, decoding would be faster if we could get away with using a smaller MLP, i.e. one with a smaller number of neurons and/or hidden layers. However, if we just use a smaller MLP without any other measures the reduced MLP’s capacity is not sufficient anymore to faithfully represent the whole scene. The simple idea underlying KiloNeRF is to first subdivide the scene into a coarse voxel grid and assign a separate MLP to each voxel cell. Since each of these MLPs only has to represent a small part of the scene tiny MLPs suffice to represent the scene with high detail.
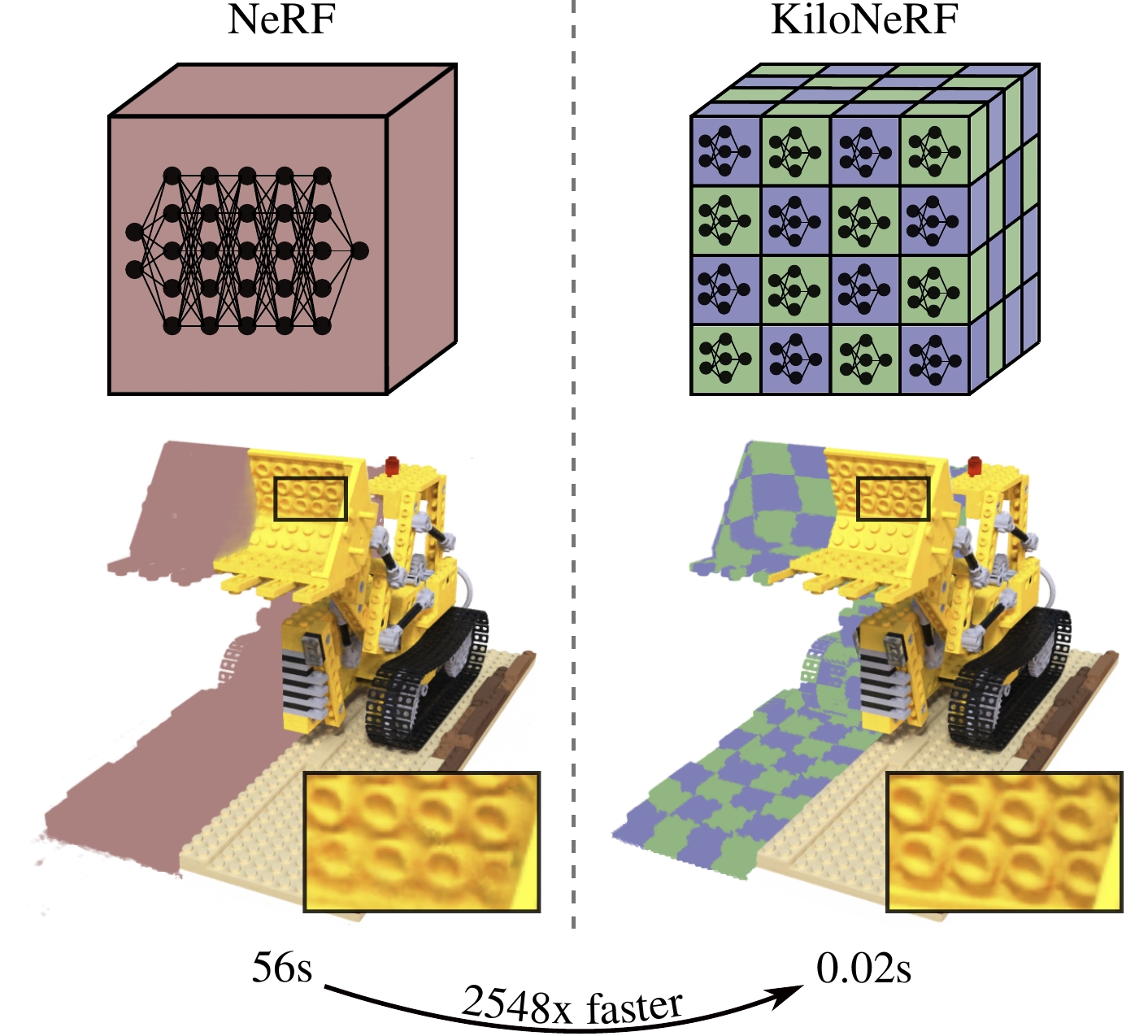
In combination with standard optimization techniques from volumetric rendering, we demonstrate that real-time rendering with a resolution of 800x800 can be achieved. Without sacrificing any visual fidelity KiloNeRF requires less than 100 MB of memory to store a scene. While this is more than the 5 MB that a single MLP requires, compression is still sufficiently high for many practical purposes.
@INPROCEEDINGS{Reiser2021ICCV,
author = {Christian Reiser and Songyou Peng and Yiyi Liao and Andreas Geiger},
title = {KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs},
booktitle = {International Conference on Computer Vision (ICCV)},
year = {2021}
}
Tabulation-based approaches
Another conceptually straightforward idea is to convert NeRF’s representation into a discrete representation after training. However, naively converting a radiance field into a 5-dimensional table would require tens of gigabytes of memory, which exceeds what current GPUs offer. Three recent works (Garbin et al., 2021, Yu et al., 2021, Hedman et al., 2021) show that by cleverly dealing with the view-dependent color the storage impact can be significantly decreased. For instance, PlenOctrees make use of spherical harmonics, which allow compact encoding of functions defined on a sphere. In a Sparse Neural Radiance Grid (SNeRG), view-dependent color is encoded as a low-dimensional feature vector that can be efficiently decoded with a tiny MLP. A clear advantage of these methods over KiloNeRF is that the tabulation-based approaches enable real-time rendering of higher resolution outputs on older/cheaper hardware. There is still ample potential for optimization of KiloNeRF by making use of the Tensor Cores present in more recent consumer GPUs, which might also enable KiloNeRF to render HD images in real-time. A disadvantage of the tabulation-based approaches is that they signficiantly increase GPU memory and/or hard disk consumption as these methods require several gigabytes of memory. For small and medium-sized scenes this does not yet pose a big problem since current GPUs offer sufficient amounts of memory, but scaling to larger scenes quickly leads to running out of memory. SNeRG demonstrates that with help of standard image codecs like PNG or JPEG their representation can be compressed to less than 100 MB of memory. This greatly helps with decreasing disk consumption and transmission times. However, since PNG/JPEG decoding has to happen prior to rendering GPU memory consumption cannot be reduced with this additional compression step. Therefore scalability remains an aspect where KiloNeRF’s approach might be advantageous. That being said, there are numerous works (Rodríguez et al., 2014) from the volumetric rendering community that encode volumes such that transient decompression is possible, i.e. the full volume does not need to be present in decompressed form on the GPU for rendering. It might be thus interesting to use these codecs on tabulated data and see how this compares in terms of compression ratio and decoding speed to KiloNeRF.
Neural Geometric Level of Detail
Similar to KiloNeRF, Neural Geometric Level of Detail (NGLOD) also speeds up inference by using smaller MLPs to represent the scene. However, NGLOD does not employ MLPs that are only responsible for a particular region of the scene. Rather, each of their MLPs is responsible for the whole scene. To reduce the required parameter count of their MLPs they condition on local features, that are tri-linearly interpolated before being fed into the MLP. To be able to compactly store the scene their representation supports multiple levels of detail (LODs), where the higher LODs are only defined for geometrically complex regions. Each LOD is represented by a separate MLP. Their approach enables real-time rendering and leads to high compression ratios. However, NGLOD is trained from 3D supervision and only encodes geometry, while in the NVS setting only multi-view supervision is available and both geometry and view-dependent color needs to be encoded. It would be interesting to adapt NGLOD for this more difficult setting and see how it compares to KiloNeRF.
Light Field Networks
In NeRF, to render each pixel a ray is cast through that pixel and the representation has to be evaluated for many query locations along the ray. Light Field Networks (LFN) and Neural 4D Light Fields do away with this requirement for multiple samples along the ray by directly learning the mapping from ray origin and ray direction to the pixel’s RGB value. This does not impose the same inductive biases as the volumetric rendering employed by NeRF and therefore some additional learned or handcrafted priors are necessary. The network is only evaluated once per pixel and therefore rendering is greatly sped up. Since the scene is represented by a single MLP the storage requirements are as low or even lower than NeRF’s. However, these approaches assume that the color along each ray is constant, which limits generality.
Outlook
There is some promising progress in adopting neural coordinate-based representations for real-time applications. An interesting avenue for future work is to scale these approaches to larger scenes.



