

3D reconstruction is a fundamental problem in computer vision with numerous applications, for example, autonomous driving and AR/VR. With the recent explosive development of deep neural networks, learning-based 3D reconstruction techniques have gained popularity.
In our previous project Occupancy Networks (ONet), we tried to answer the question: “What is a good 3D representation for learning-based systems?” We proposed to represent 3D geometry as the decision boundary of a classifier that learns to separate the object’s inside from outside. This yields a continuous implicit surface representation that can be queried at any point in 3D space. Watertight meshes can be then extracted in a simple post-processing step. Compared to explicit representations like point clouds, voxels and meshes, we have shown that this implicit neural representation does not require discretization of the 3D space (e.g. into voxels or points) and is able to represent 3D shapes at arbitrary resolution. See the comparison below, where the rightmost one is the reconstruction of our implicit model.
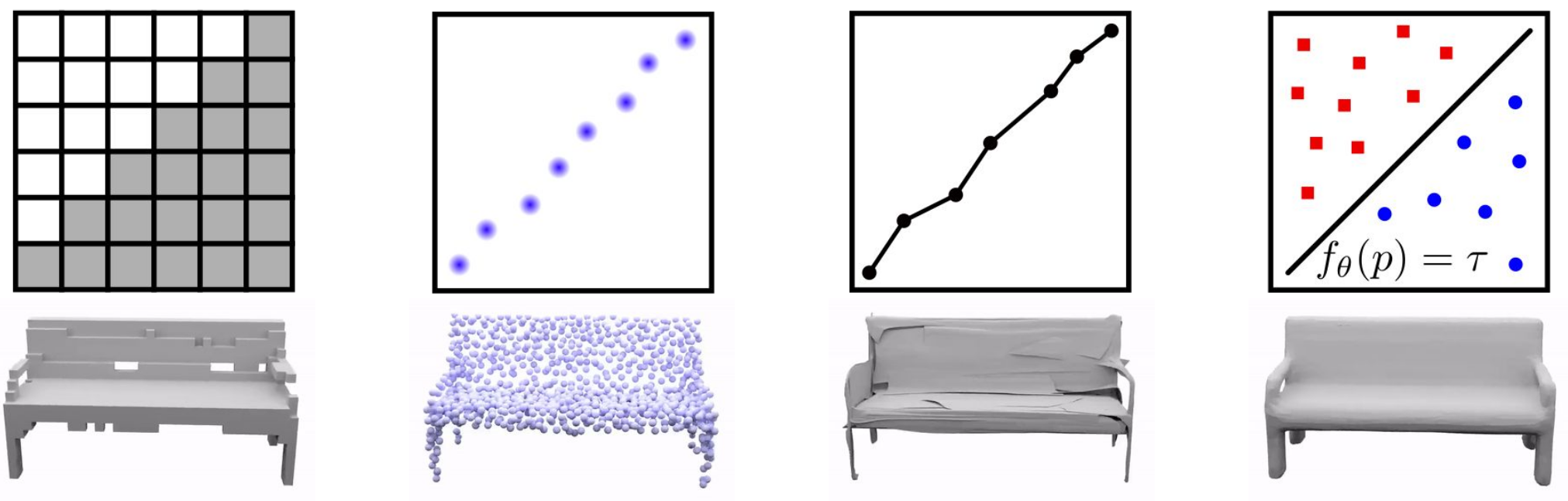
The Challenge
While implicit representations have greatly improved 3D reconstruction of single objects, we would also like to scale such models to large scenes. However, existing approaches usually condition only on a global feature, which does not capture local information, and hence fail in reconstructing details. As you can see below, ONet (left) fails to reconstruct such an indoor scene on the right.

Therefore, in our recent ECCV 2020 spotlight paper Convolutional Occupancy Networks, we investigate how we can scale implicit 3D representations to large scenes by combining the benefits and inductive biases of classical convolutional neural networks (eg, translation equivariance) with implicit neural representations.
How do we achieve this goal?
Our Approach
The idea is surprisingly simple. Given some kind of input, e.g. a sparse and noisy point cloud, we pass it through some feature extractor to acquire point-wise features. Next, we project and aggregate the point features into a pre-defined discrete 3D grid structure.

So far, the feature volume only contains local features from the sparse input points. In order to acquire also global information, we apply a convolutional hourglass network (U-Net) to process the feature volume. Now, both local and global information have been integrated into the processed feature volume.
Our key observation is that given this discrete feature volume, the occupancy of any point in continuous 3D space can be determined by interpolating nearby features. Unlike in the original ONet where every point uses the same global feature, our method queries a feature for each point from the processed feature volume by trilinear interpolation.
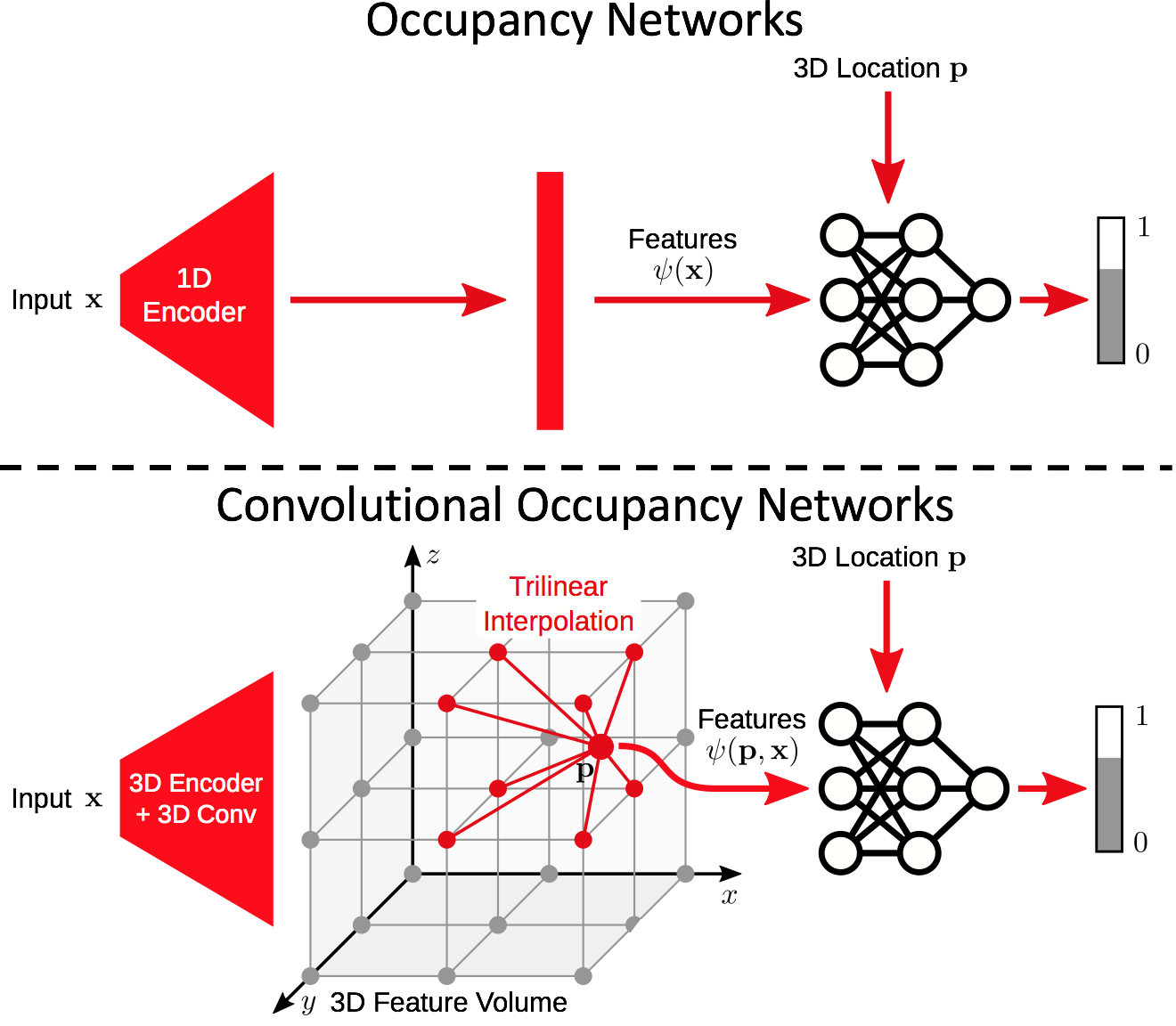
This is basically the idea! In addition to the 3D feature volume, we also explore the use of canonical plane(s) to store features. If you are interested, please have a look at our paper.
Does it work?
We first evaluate on a synthetic room dataset, where the input is a noisy point cloud. Compared to ONet (middle), our approach (right) can produce detailed and smooth 3D reconstruction.

We can also take the model trained on this synthetic room dataset, and directly apply to the real-world dataset ScanNet. We demonstrate that our model generalizes reasonably well from synthetic to real data:

Furthermore, we can also train on small synthetic crops from our synthetic room dataset, and perform 3D reconstruction in a sliding-window manner on very large scenes. In the teaser video, we reconstruct a two-floor building with the size of $15.7m \times 12.3m \times 4.5m$. Below we show another example of the reconstruction of an ancient site.

Further Information
To learn more about Convolutional Occupancy Networks, watch our video here:
For more detailed information, check out the paper and supplementary. If you are interested in experimenting with ConvONet yourself, run the source code of our project. We are happy to receive your feedback!
@inproceedings{Peng2020ECCV,
title = {Convolutional Occupancy Networks},
author = {Peng, Songyou and Niemeyer, Michael and Mescheder, Lars and Pollefeys, Marc and Geiger, Andreas},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}



