
Label Efficient Visual Abstractions for Autonomous Driving
Recent Artificial Intelligence (AI) systems have achieved impressive feats. Human world champions were convincingly defeated by AI agents that learn policies to play the board game Go as well as video games Starcraft II and Dota 2. These policies map observations of the game state to actions using a Deep Neural Network (DNN). However, AI systems designed to operate in the physical world, such as self-driving vehicles, do not observe a concise game state summarizing their surrounding environment. Typically, these systems initially perform perception, processing information from sensors (like a camera or LiDAR) into a scene representation, which acts like a game state. They then perform control, where this scene representation is input to a policy that outputs an action (steering angle, throttle and brake values).
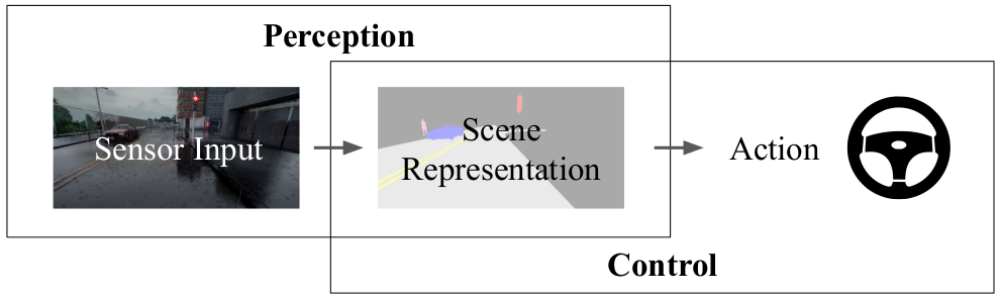
What is a Good Scene Representation?
A good scene representation should contain only the information relevant to the driving task, with as little additional information as possible. One example of a scene representation is a semantic segmentation map, which classifies each image pixel into a category (such as road, lane marking, pedestrian, or vehicle).

Previous work has shown that semantic segmentation is an effective scene representation for urban autonomous driving. However, obtaining a training dataset with accurate annotations for semantic segmentation is expensive. For instance, labeling a single image was reported to take 90 minutes on average for the Cityscapes dataset. So far, there has been no systematic study on label efficiency when using semantic segmentation maps as scene representations. Therefore, in our recent work Label Efficient Visual Abstractions for Autonomous Driving, we look into the following question - can scene representations obtained from datasets with lower annotation costs be competitive in terms of driving ability?
Our Study
The two key ideas we leverage to improve label efficiency are:
- Considering only safety-critical semantic categories and combining several non-salient classes (e.g., sidewalk and building) into a single category.
- Using coarse 2D bounding boxes to represent objects such as pedestrians, vehicles and traffic lights.

Results
We conduct extensive experiments on the CARLA NoCrash benchmark. One of our key findings is that limiting the representation to six semantic classes (road, lane markings, pedestrians, vehicles, red lights and green lights), surprisingly leads to improved performance when compared to the commonly-used set of fourteen semantic classes. In our paper, we demonstrate improved driving performance while reducing the total time required to annotate the training dataset from 7500 hours to just 50 hours.

Moreover, we observe significantly better driving performance and more consistent, reproducible results with different random seeds for training than state-of-the-art image-based methods such as CILRS (Codevilla et al., 2019).

Further Information
To learn more about work, we invite you to watch our talk:
More information (including the paper and source code) is available on our project page.
@inproceedings{Behl2020IROS,
title = {Label Efficient Visual Abstractions for Autonomous Driving},
author = {Behl, Aseem and Chitta, Kashyap and Prakash, Aditya and Ohn-Bar, Eshed and Geiger, Andreas},
booktitle = {International Conference on Intelligent Robots and Systems (IROS)},
year = {2020}
}



