
Generative Radiance Fields for 3D-Aware Image Synthesis
Generative adversarial networks have enabled photorealistic and high-resolution image synthesis. But they have one limitation: Say we want to rotate the camera viewpoint for the cars below, then generic GANs cannot model this explicitly.
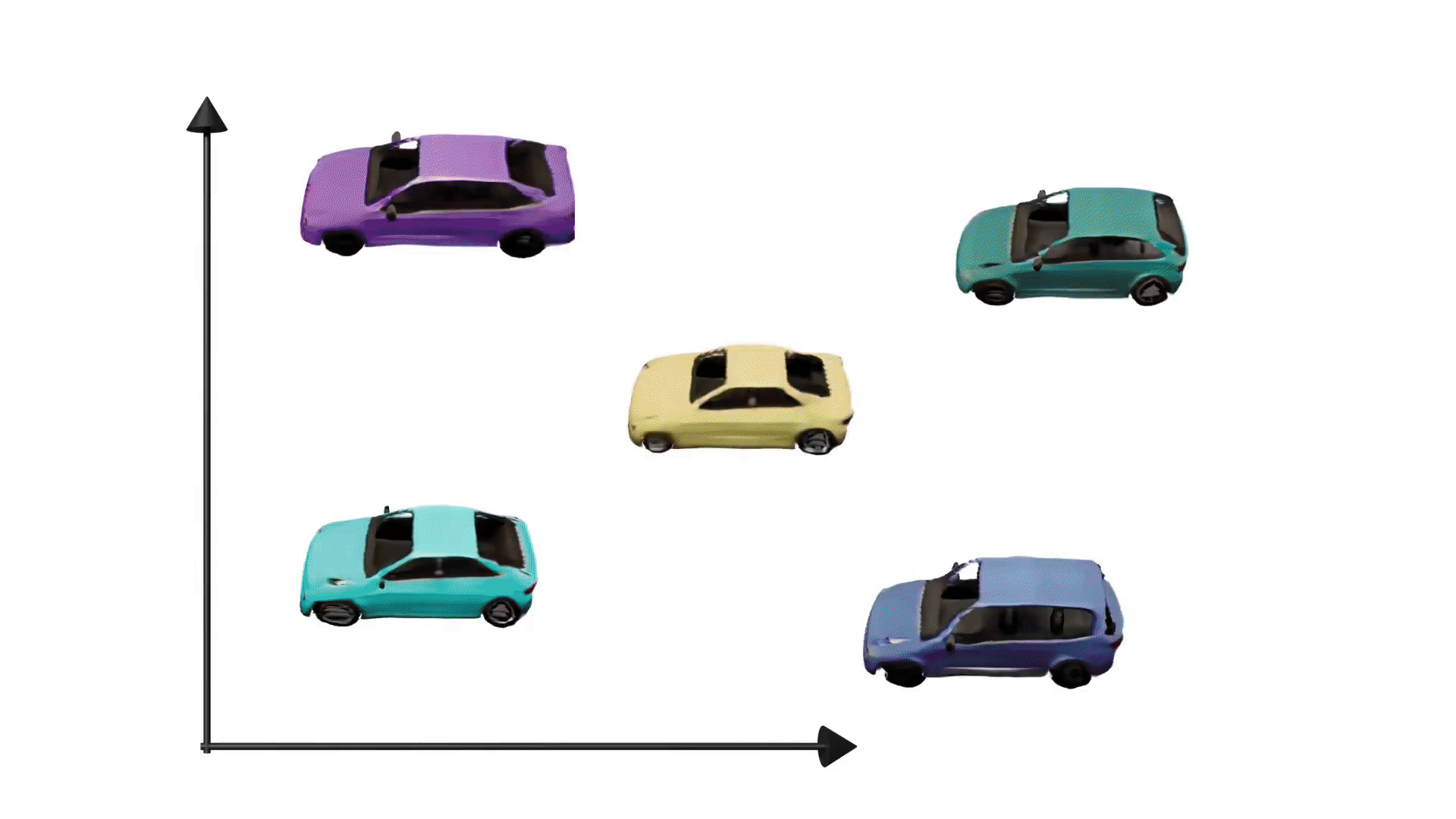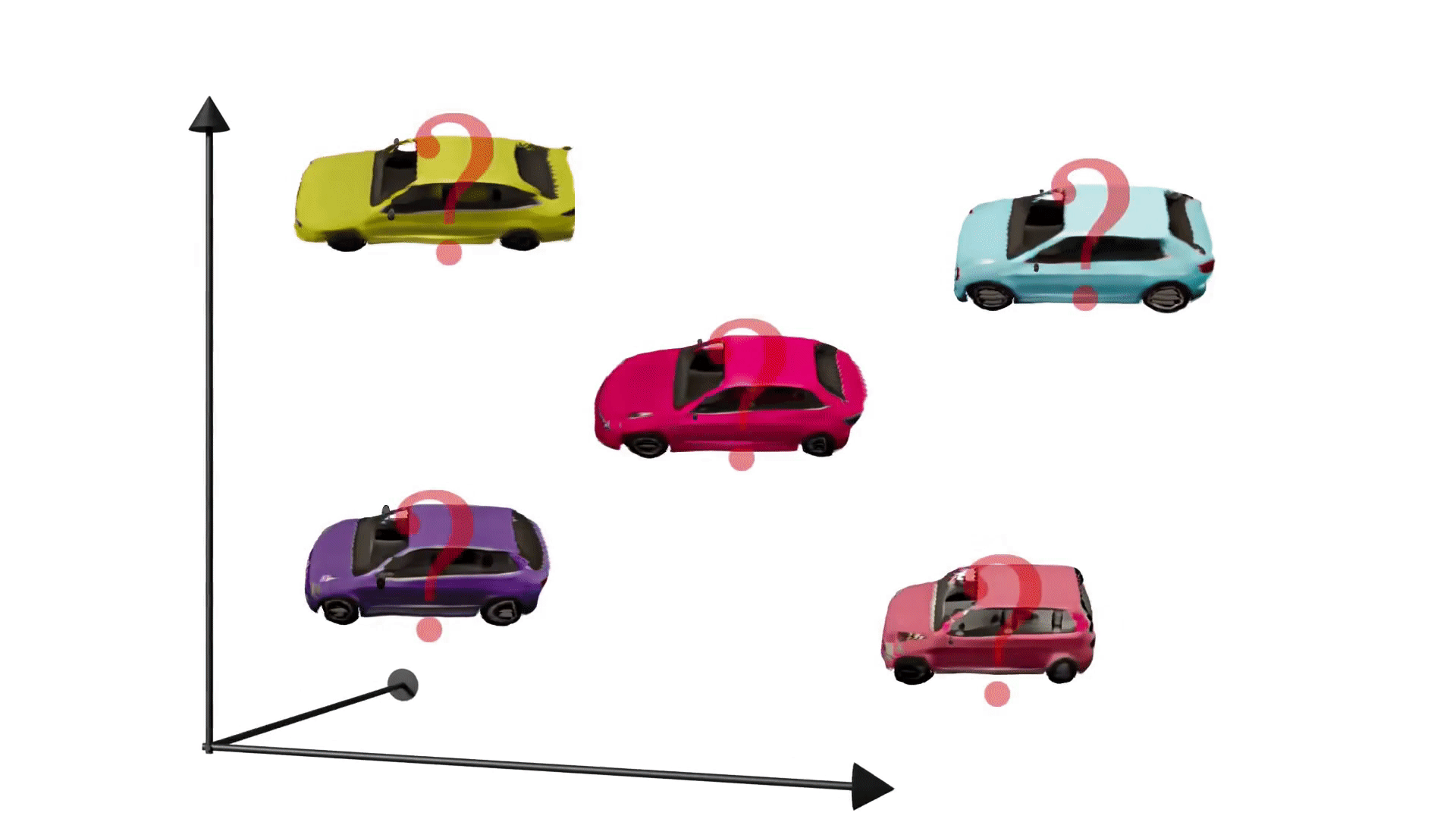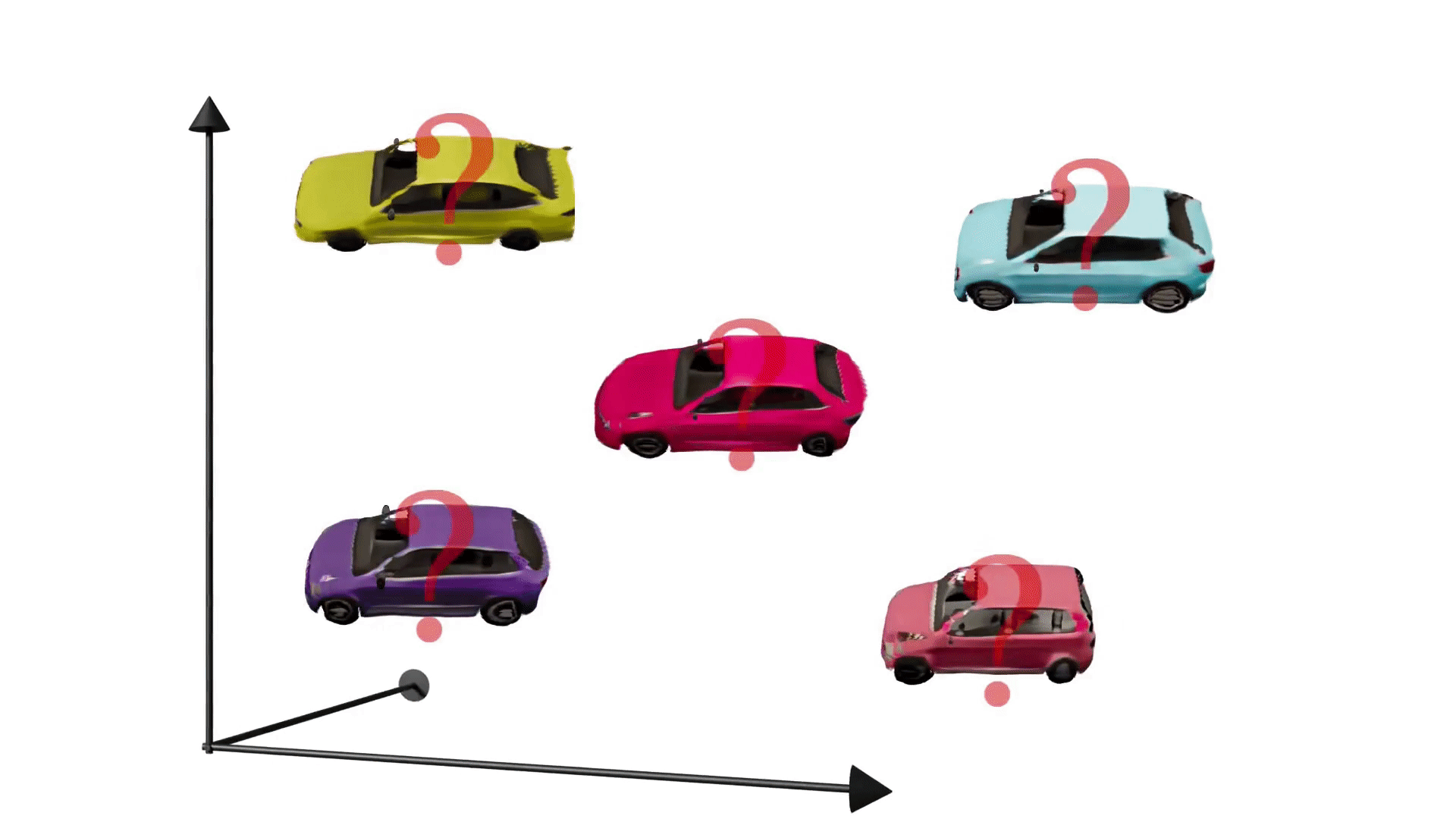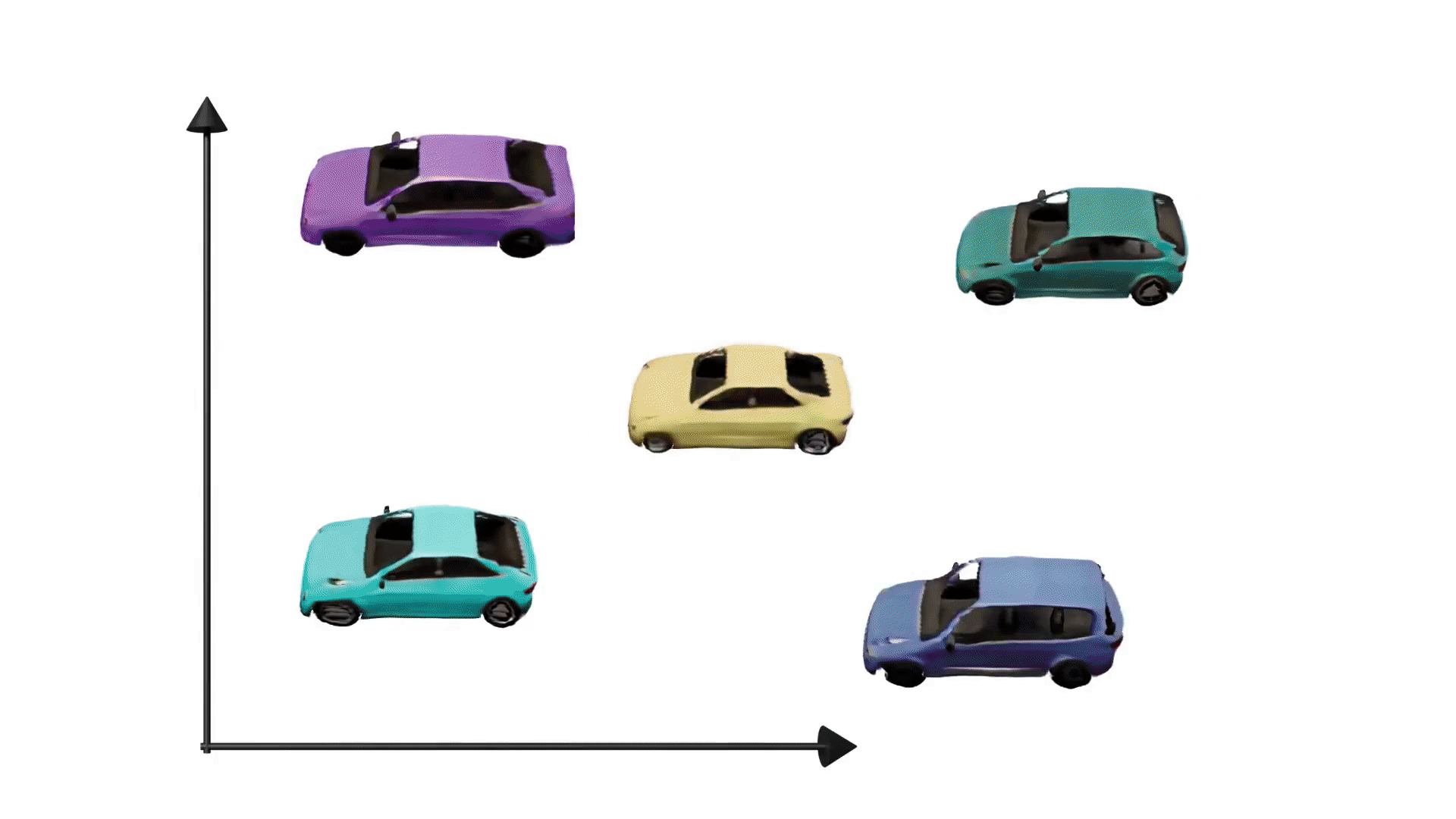
To truly leverage the power of generative models for content creation, e.g. for virtual reality or simulation, it is important to take the 3D nature of our world into account. Therefore, our goal is to make generative models 3D-aware. Importantly, we want to achieve this without using 3D supervision, e.g. 3D shapes or posed multi-view images, because this information can be difficult to obtain for real world data. In a nutshell, the research question we address in this project is:
How can we create a 3D-aware generative model that can learn from unposed 2D images only?
How to design a 3D-aware GAN
Generic generative models create images from a low-dimensional latent code that represents properties like shape or appearance of the object.
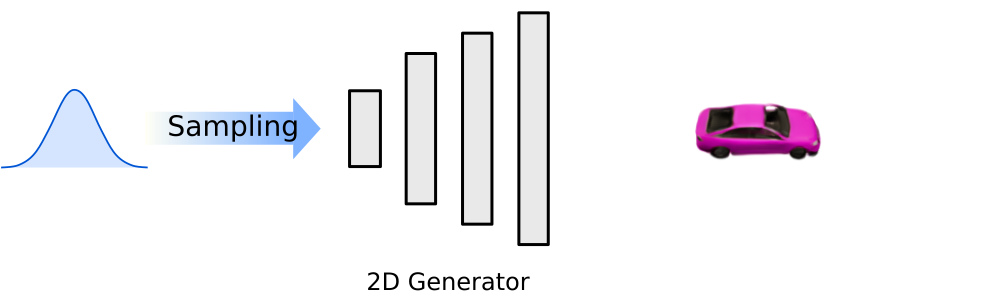
We can incorporate 3D-awareness by adding a virtual camera to the model. This introduces two additional components:
- A 3D representation of the generated objects, parameterized by a 3D Generator
- A virtual camera and a corresponding renderer that produces an image of the 3D representation

The key contribution of GRAF lies in a clever choice of these components. Previous works ( Nguyen-Phuoc et al., 2019, Henzler et al., 2019 ) use voxel-based 3D-representations. The problem with voxels is that they scale cubically in memory with increasing size. Inspired by NeRF, we instead represent the 3D-object with a continuous function, namely a Generative RAdiance Field (GRAF). As evidenced by our experiments, this allows to generate 3D-consistent images, scales better to high resolution and requires only unposed 2D images for training.
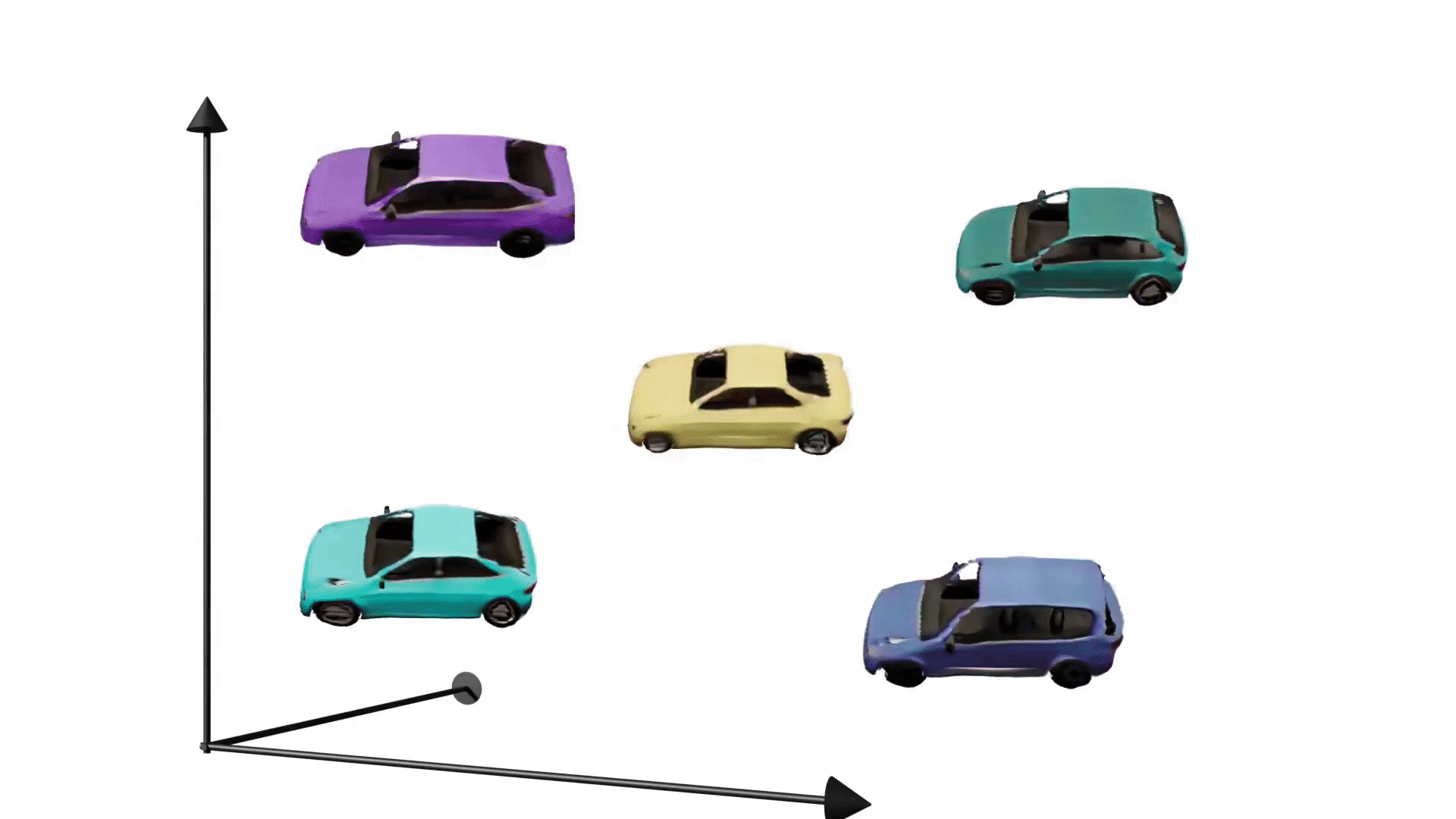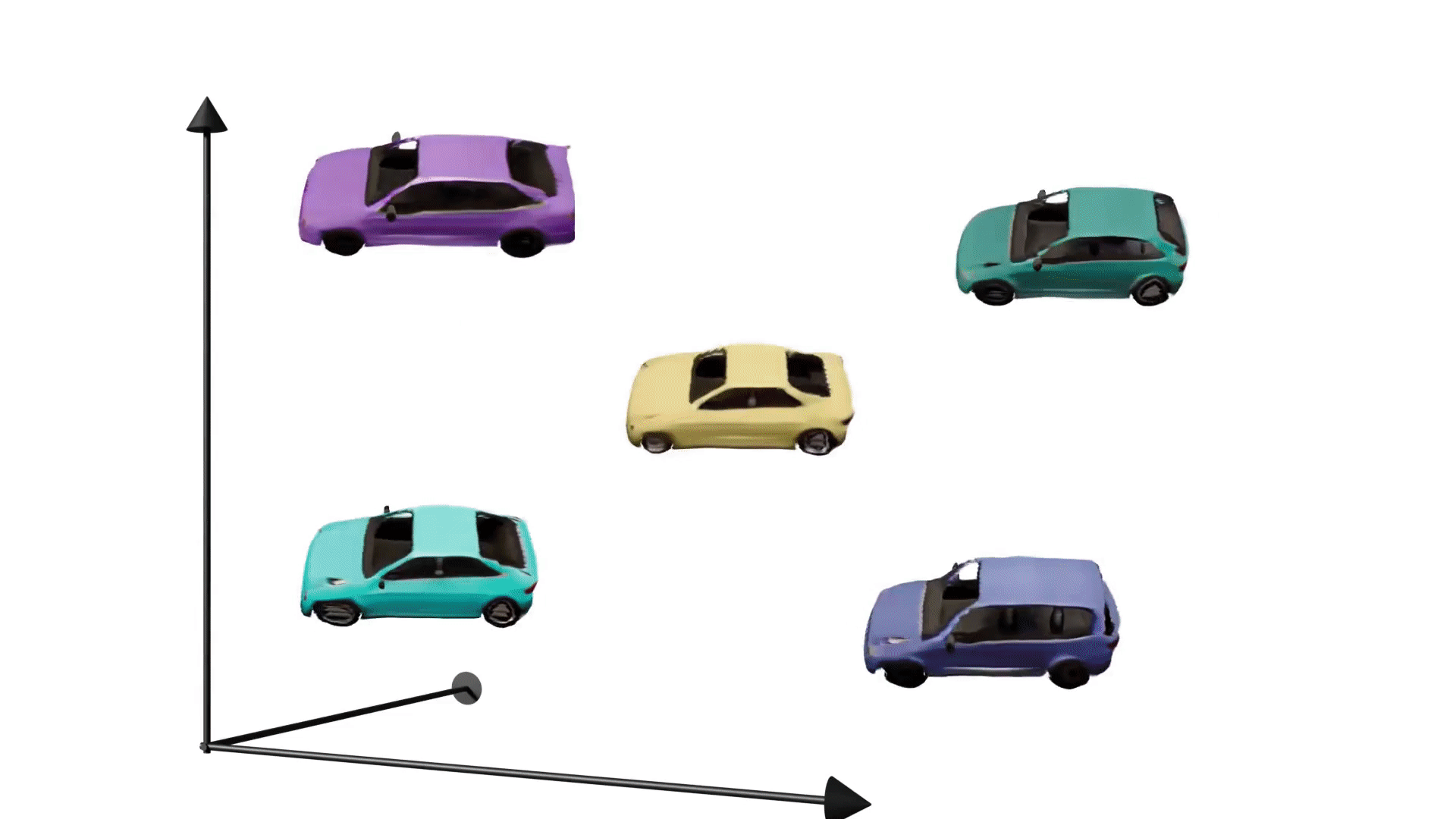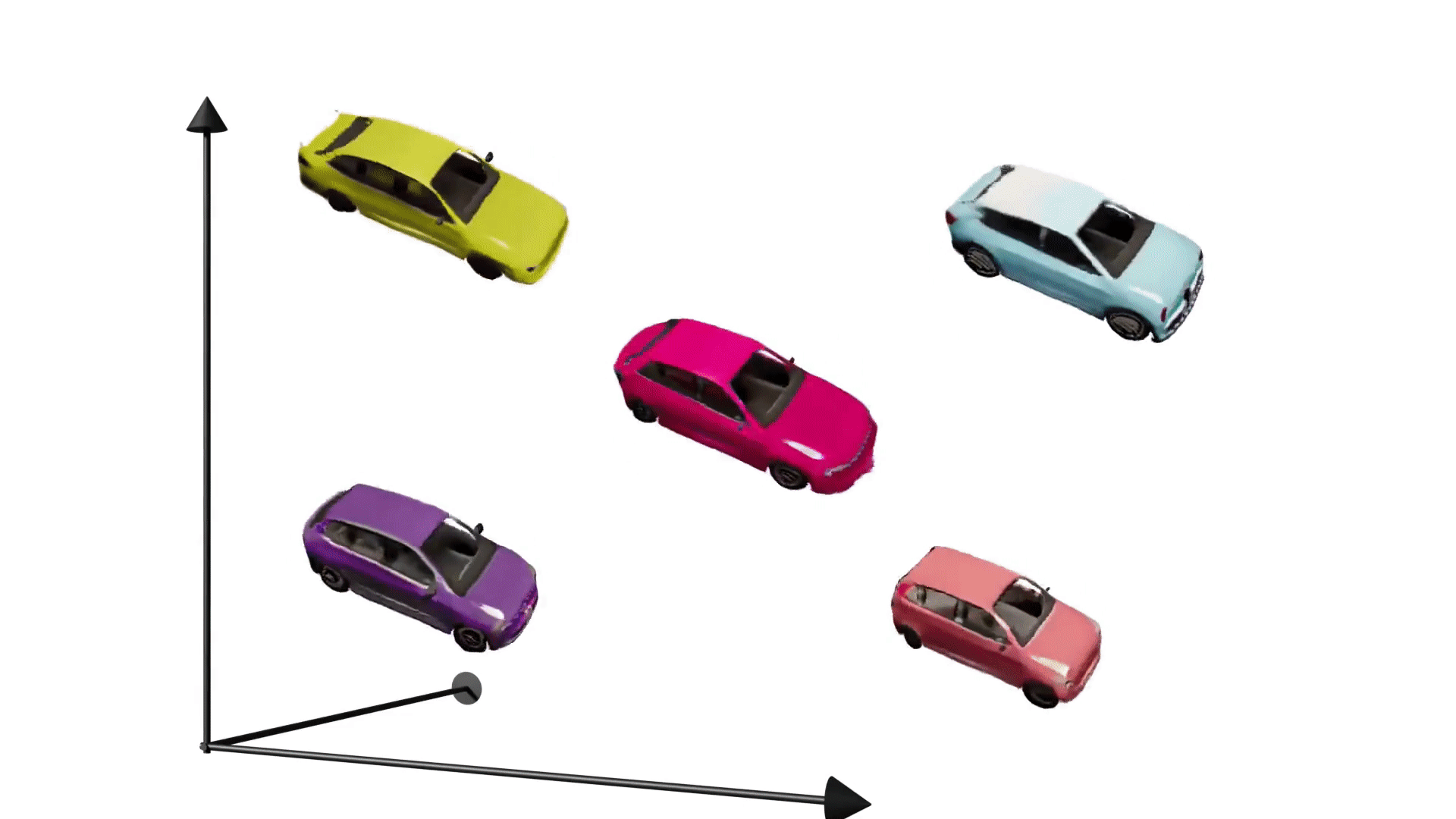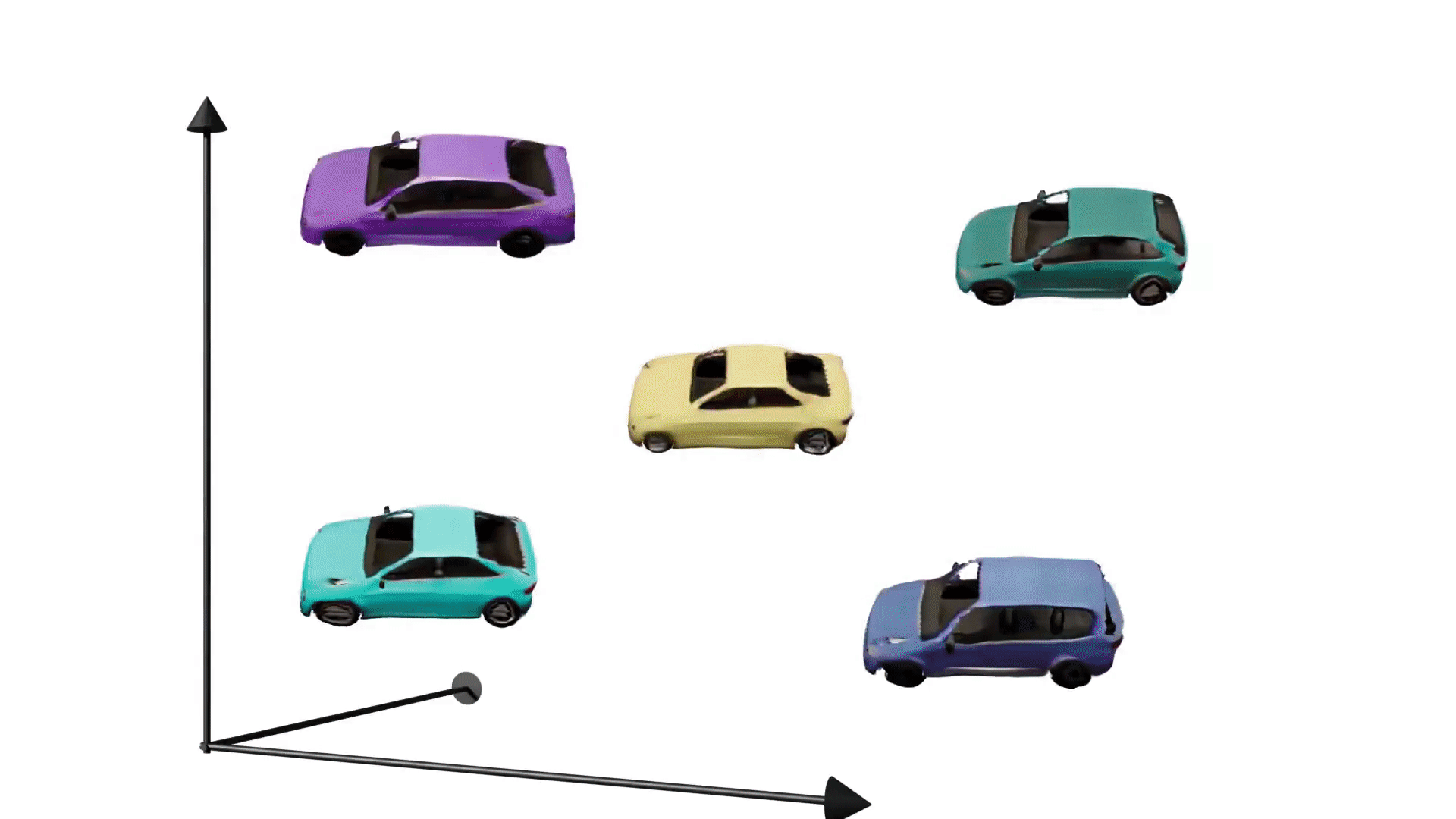
Spin it around!
With GRAF, we can now render images from different viewpoints by controlling the pose of our virtual camera in the model.
And of course our method works not only on synthetic cars! For example, we can train the network using chair images:

Remember, that the network only saw unposed 2D images during training which makes generating 3D objects a difficult endeavor. Nonetheless, GRAF also works reasonably well for natural images.



Go into depth!
One benefit of generative radiance fields is that they additionally produce a depth map to every RGB image.


Play around!
Moreover, instead of using a single latent code to model the entire image like generic GANs, GRAF models shape and appearance separately using two disentangled latent codes and allows for modifying them separately. As a result, we can play around with shape and appearance of the generated objects, respectively.
Modifying only shape:

Modifying only appearance:

Curious?
For more details, including a nice visualization of generative radiance fields, watch our 3-minute video:
Further information (including the paper and supplementary) is available on our project page. If you are interested in experimenting with GRAF yourself, download the source code of our project and run the examples. We are happy to receive your feedback!
@inproceedings{Schwarz2020NEURIPS,
title = {GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis},
author = {Schwarz, Katja and Liao, Yiyi and Niemeyer, Michael and Geiger, Andreas},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2020}
}



