What do you see in the following images?

If you answered Camel, Cow, Camel, and Cow, well done! In many instances, machine learning models are not that smart yet. If we collect a dataset for this Camel-Cow classification task, images in the dataset will typically depict cows on green pastures and camels in the desert. The most straightforward correlation a classifier can learn is the connection of the label “cow” to a grass-textured background and of the label “camel” to a sandy background. There are many more such examples, known as shortcuts, e.g., Clever Hans or the Tank Legend. Learning those shortcuts becomes problematic if the test data does not follow the training distribution - in our example, an image of a cow in the desert. In the causality literature, such a correlation is called spurious.
Causality also aims to answer counterfactual questions like “How would this image look like with a different background.” If we were able to answer this question, we could generate images of unseen combinations, i.e., cows in the desert, and supply them to our classifier. Training on this counterfactual data would increase robustness against spurious correlations.
Generative Models struggle too!
So, let’s generate counterfactual images! Unfortunately, it is not that easy with standard generative models like a VAE. Consider the simple example of colored MNIST, a digit-classification dataset, where each digit is strongly correlated with a specific color (left). If we train a VAE on this dataset, its latent space will look like on the right:

There are nice clusters of red zeroes, yello eights, etc. But there is not a single blue zero – the different factors of variation (FoV) in the data are not disentangled.
Building a Counterfactual Generative Network
How do we get direct control over these factors? And how can we scale our generative model beyond toy datasets so we generate realistic-looking images? The main idea is to structure the generative network into several subnetworks, so-called independent mechanisms. Each of them is responsible for one FoV. In the image below, there are three mechanisms, shape $\mathbf{m}$, foreground $\mathbf{f}$, and background $\mathbf{b}$. We composite their output into the final image $\mathbf{x_{gen}}$. During training, all mechanisms receive the same label, here “ ring-tailed lemur.” We refer to the whole model as Counterfactual Generative Network (CGN).
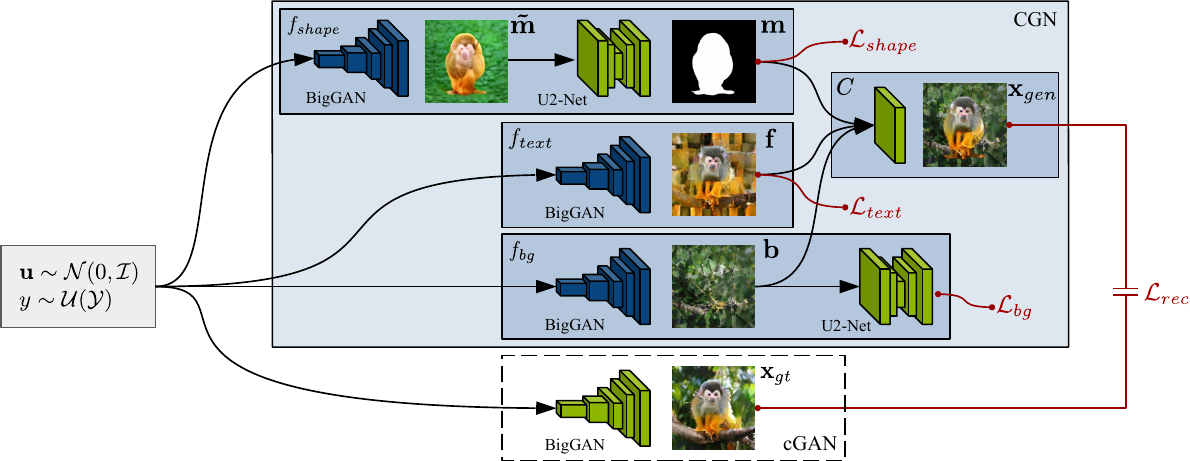
By choosing appropriate losses for the optimization, we can disentangle the signal, e.g., generating a background without any object. With the help of pre-trained models (BigGAN, U2-Net), we scale the CGN to ImageNet, a large dataset that remained out of reach for previous disentanglement methods.
Generating Counterfactuals
To generate counterfactual images, we can now sample a noise vector, generate an image, and ask: “How would this image look like if the object had a cheetah texture?” Answering this questions is as simple as supplying the cheetah label to the texture mechanisms to generate the cheetah texture. We have now full control over the FoVs for the generative process:

The counterfactual images with randomized labels can look quite funny and intriguing:

Training on these images results in the desired effect of less reliance on backgrounds or textures. Another cool find is that a CGN does interesting things during training, like generating high-quality binary object masks and unsupervised image inpainting.

From left to right: mask, foreground, background, and composite image over the course of training.
Fun & Further Information
In GAN literature it is common to visualize the latent space with a latent walk, i.e., sampling and interpolating between points in the latent space. Latent walks are way more interesting if we sync them to music! So, see below the Counterfactual Latent Dance, a musical video / latent walk with a CGN.
Another fun application is to use the generated textures for image stylization. We walk through the latent space of the texture mechanism and optimize the input image to follow the style of the generated texture:

Further information (including the paper and code is available on our project page. If you want to generate counterfactual images directly in your browser, you can try the Colab.
@inproceedings{Sauer2021ICLR,
title = {Counterfactual Generative Networks},
author = {Sauer, Axel and Geiger, Andreas},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2021}
}



