

TL;DR: We incorporate a compositional 3D scene representation into the generator model such that at test time, we can control individual objects in the scene during image synthesis.
Introduction
Generative models are great! In the typical setting, we train our generator model on a large collection of images of some domain $X$, and at test time, we can draw new samples from our prior distribution $p_z$ and get new outputs in the same domain $X$:
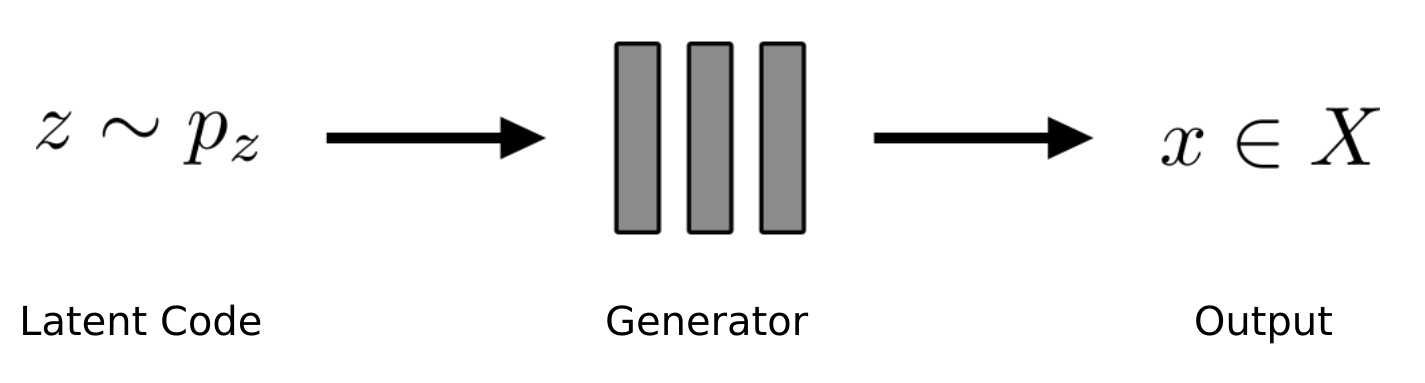
Let’s imagine our domain $X$ are images of cars. Once training has finished, we can then generate millions of images of new cars! In particular convolutional neural network-based methods have led to impressive results for this task, e.g., the following cars are generated using the state-of-the-art StyleGAN2:

The Challenge
In practice, we often do only want to generate new images, but we would like to have control over the synthesis process. But how do we need to change the model to control the scene, i.e., how can we move the car to the right or the top?
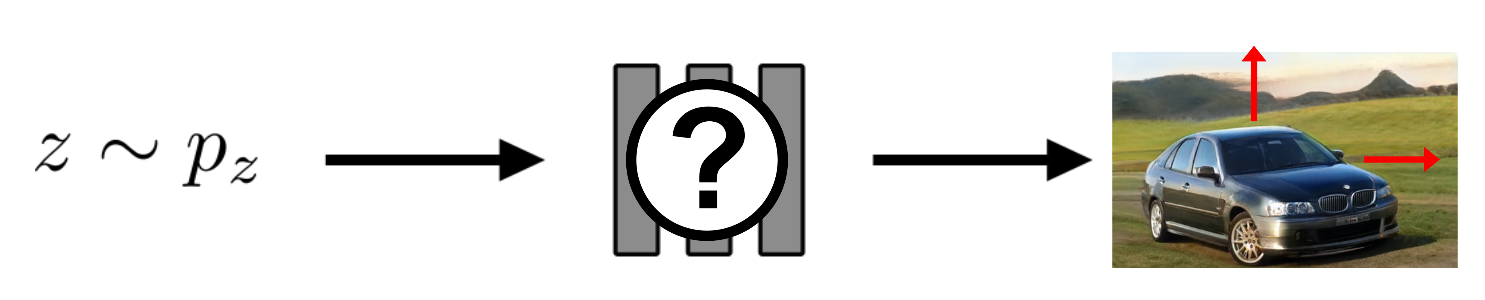
It turns out that this problem is quite hard! One reason for this is that if we would like to easily move objects around, rotate them, and change the camera viewpoint, the model needs to perform some form of reasoning in 3D. Further, the model has to encapsulate individual objects in the scene to allow for controlling them individually. It remains unclear how we can achieve this when our model operates only in 2D.
Our Approach
Our main idea is to incorporate a compositional 3D scene representation into the generator model:
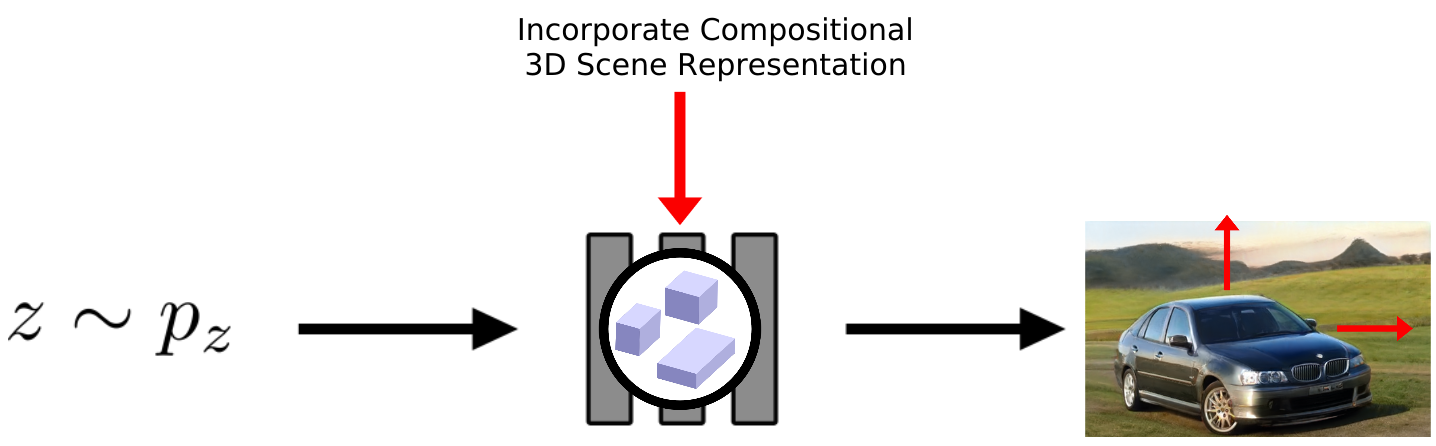
More specifically, in each forward pass we sample individual latent codes for the objects in the scene as well as the background. These give us individual feature fields in a canonical space. A feature field is a function which maps a 3D point and viewing direction to a density value and a feature vector. We then sample a pose for each object such that we can composite them into a single scene. Next, we sample a camera pose and volume render a feature image of the scene. A 2D neural renderer then upsamples the feature image and outputs the final RGB rendering:

Note that although we train our model from raw, unposed image collections, we are able to incorporate a 3D bias into our generator model. Further, we facilitate the decomposition of the scene into individual objects while no supervision is necessary!
Sounds cool, but does it actually work?
Here we show some results for moving the object around and rotating it when we train on a collection of images of cars:

Note how the background doesn’t change while we move the car around. Our model clearly disentangles fore- from background!
Similarly, we can also change the latent shape and appearance codes while we keep everything else fixed. Here we show a shape interpolation (top) as well as an appearance interpolation (bottom):

We can also interpolate between different backgrounds while keeping the car fixed:

Finally, we can even add more cars to the scene! Keep in mind that we trained our model on a dataset which contains only images of single cars:

Further Information
To learn more about GIRAFFE, watch our video here:
For more detailed information, check out the project page, the paper, and the supplementary. If you are interested in experimenting with GIRAFFE yourself, download the source code and run the demo!
@inproceedings{Niemeyer2020GIRAFFE,
author = {Michael Niemeyer and Andreas Geiger},
title = {GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields},
booktitle = {Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year = {2021},
}



