
KITTI-360
Since the 1960s, several major subfields of artificial intelligence like computer vision, graphics, and robotics have developed largely independently. But the community has recently recognized that progress toward self-driving cars requires an integrated effort across different fields. This motivated us to create KITTI-360, successor of the KITTI dataset, a new suburban driving dataset which comprises richer input modalities, comprehensive semantic instance annotations and accurate localization to facilitate research at the intersection of vision, graphics and robotics. To get an overview of the dataset, we invite you to enjoy our (overly) dramatic cinematic video trailer that we have produced.
Online Benchmarks
Recently, we opened up all our evaluation servers for submission. In this blog post, we are excited to share some of the novel and exciting tasks that KITTI-360 considers at the intersection of vision, graphics and robotics.
How to parse the scene?
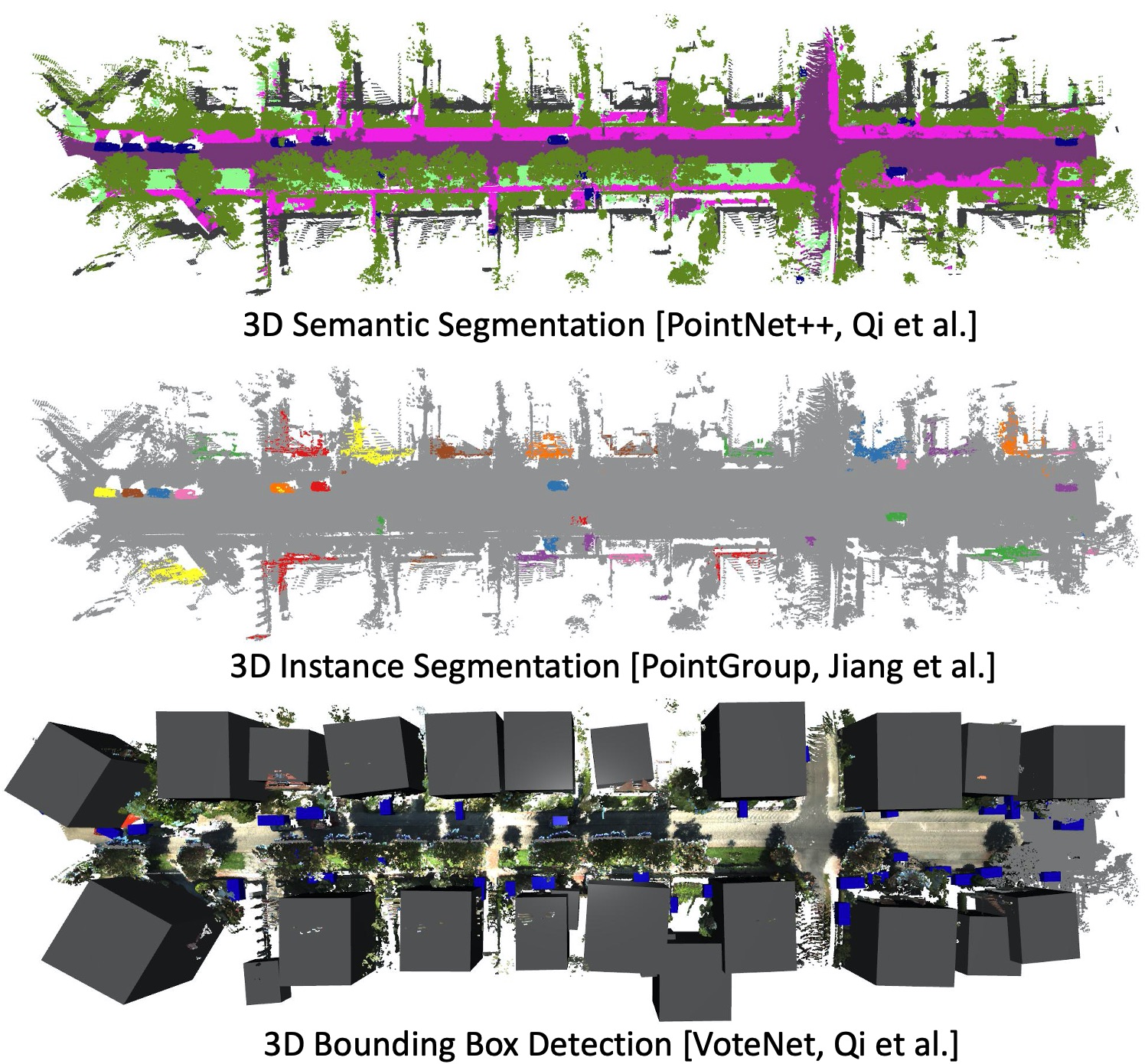
Semantic scene understanding is one of the key capabilities of autonomous driving vehicles. With KITTI-360, we establish scene perception benchmarks in both 2D image space and 3D domain:
- 2D Semantic/Instance Segmentation
- 3D Semantic/Instance Segmentation
- 3D Bounding Box Detection
- Semantic Scene Completion
We evaluated several baselines to bootstrap the leaderboards and assess the difficulties of the tasks:
For some of the tasks, we show interactive plots to illustrate results of the submission on our website. Here is an example for the semantic scene completion task:
How to simulate the scene?
Simulation is an essential tool for training and evaluating autonomous vehicles. Imaging a simulator providing both RGB images and semantic information with no domain gap to the real-world, wouldn’t it be great? Towards this goal, we establish challenging benchmarks:
- Novel View Appearance Synthesis
- Novel View Semantic Synthesis
For novel view appearance synthesis, we evaluated several state-of-the-art methods, including NeRF-based methods. For novel view semantic synthesis, we evaluate naïve baselines by applying an existing semantic segmentation model to the synthesized images. Here we show results of mip-NeRF as an example:

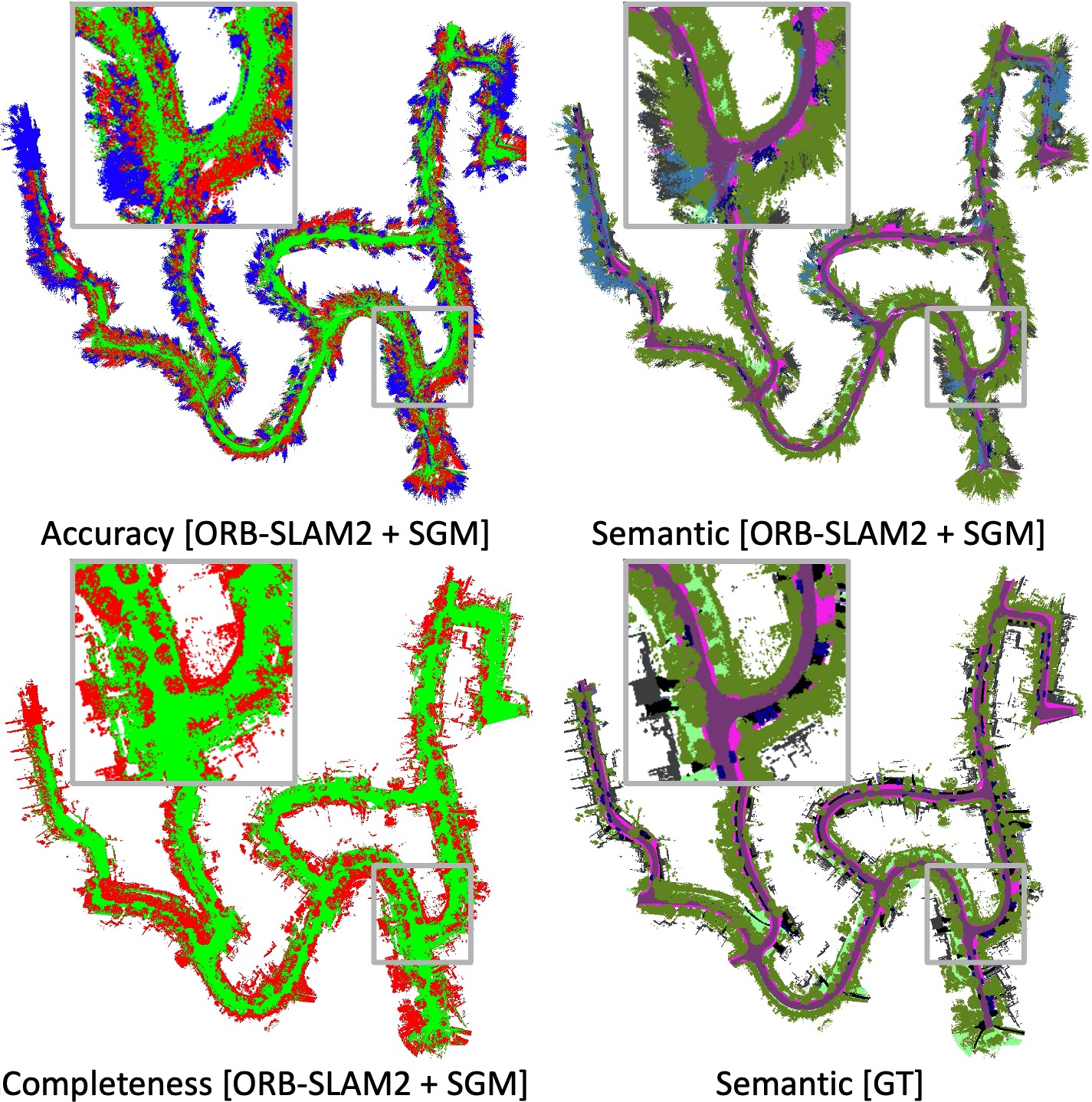
How can semantics benefit SLAM?
We also establish a semantic SLAM benchmark at the intersection of robotics and computer vision to investigate how semantics can benefit SLAM. Existing works on outdoor semantic SLAM typically evaluate only pose estimation while ignoring the quality of the semantic reconstruction. Considering that the semantic reconstruction is valuable on its own for down-stream tasks, e.g. planning, we evaluate both tasks on KITTI-360:
- Localization
- Geometric and Semantic Mapping
We evaluate accuracy, completeness and semantic mIoU for geometric and semantic mapping. Here we show the results of a simple baseline by using ORB-SLAM2 for localization and fusing depth maps of semi-global matching for reconstruction:
Download and Submit
Our leaderboard has received a few exciting submissions since the release, including DeepViewAggregation for 3D semantic segmentation and Panoptic Neural Fields for novel view appearance and semantic synthesis. Are you interested in joining us? Download the training and test data on our website and try it out yourself! For each task, we provide evaluation scripts in our utility scripts.
Further Information
To learn more about our work, check out our video here:
You can find more information on our website and our paper. Our annotation tool is also publicly available. We are happy to receive your feedback!
@inproceedings{Liao2022PAMI,
title = {KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D},
author = {Liao, Yiyi and Xie, Jun and Geiger, Andreas},
booktitle = {IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI)},
year = {2022}
}



