Learning to Drive in Cities
Current self-driving systems are really good when driving on a highway (see Tesla’s autopilot and Mercedes’ intelligent drive) but they are not quite that good yet in urban environments. The reason lies in the complexities of the scenarios that the self-driving car faces: On highways, the car typically navigates on wide roads with clear markings and other road users are mostly cars, trucks and motorcycles. Driving in a city, however, introduces a large number of difficult challenges: Traffic lights and speed limits must be obeyed and people may cross roads at unexpected times and places. In particular, predicting the motion of people is an extremely hard problem. While the detection of red lights might seem like an easy problem at first glance, even for this simpler task the AI system could confuse a red light with other red patches in the camera image, like a fire hydrant, for example. Stopping for red lights is something that even advanced systems like Tesla’s autopilot can’t offer yet (Tesla is working on this problem). Waymo vehicles which traveled more in self-driving mode than vehicles of any other company, therefore operate mainly in “geofenced” regions – the car is only driving autonomously when detailed maps of streets, traffic signals, building, and other relevant infrastructure are available.

In “Conditional Affordance Learning for Driving in Urban Environments” – the result of a collaboration between ETH Zurich and Max Planck Institute for Intelligent Systems – we propose a novel self-driving technique which addreses urban scenarios and doesn’t rely on detailed maps. This new approach learns high-level representations of the world dubbed “conditional affordances” and uses them to drive with less collisions and more smoothly than previously proposed techniques. Since testing such algorithms in real world conditions is dangerous, we use the self-driving simulator CARLA which provides a realistic graphics engine as illustrated above. CARLA allows to benchmark our system against other systems in order to establish how well our approach works.
Conditional Affordance Learning
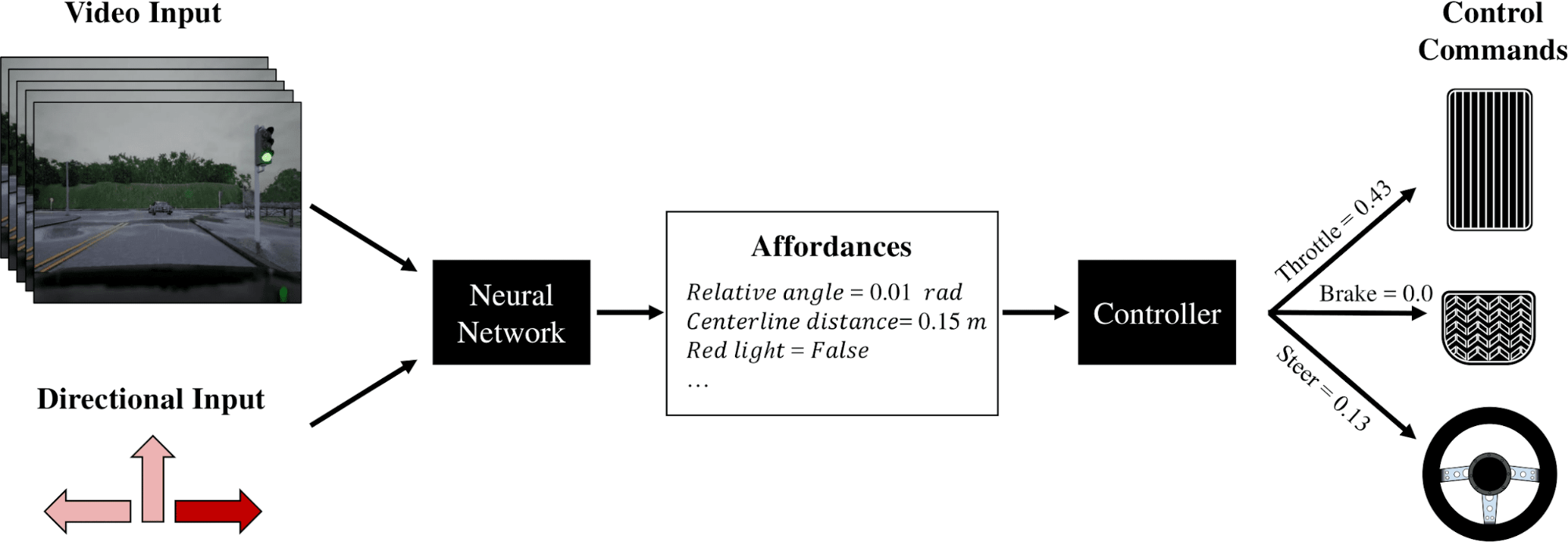
The idea behind our approach is to learn a high-level representation of the world from image pixels alone. This representation should ideally contain all information that is necessary for driving. Variables in this representation are the distance to the centerline of the lane or the presence of a red-light. We call these variables “affordances” since they limit the space of actions the vehicle can perform, and train a neural network to predict these affordances given a video and a high-level direction command (e.g., “go left at the next intersection”) as input. Based on the predictions of the neural network, we use a controller to calculate the amount of throttle, brake, and steering that should be applied.
Previous Approaches
The CARLA Benchmark offers three baseline approaches for comparison. The modular pipeline is the most common approach, employed by the majority of self-driving companies and startups. In this approach, perception, planning, and control are performed in dedicated and separated sub-modules. The output signals are then computed in a sequential fashion: Perception → Planning → Control. Another approach is to train a neural network that learns a mapping from raw input to control output end-to-end, hence eliminating the need for hand-designed modules and rules. This can be done via reinforcement learning (i.e., by using a reward signal such as the rate of infractions which occur) or via imitation learning where the goal is to imitate the actions of an expert driver. Our approach can be considered a hybrid of a modular pipeline and imitation learning as it combines end-to-end learning of high-level abstractions with classical controllers.
Key Results

Our method exhibits robust performance on the CARLA benchmark. In most situations, the agent reliably stops for red lights, stays within speed limits, follows other cars at a constant distance and stops for pedestrians. The model even generalizes to new cities that the network has not seen during training, even though the results are slightly worse in this scenario. On the CARLA benchmark, our system performs 68% better in goal-directed navigation than the previous state-of-the-art method.
Introspection
We also visualized which parts of the image the network attends to when predicting a specific affordance. We found that the network “looks” at the relevant parts of the image similar to what a human would do. For example, when looking for a red light it observes the sidewalk, where traffic lights are usually located. We were particularly surprised that during some sequences the network recognizes crossing pedestrians as obstacles even before they appear in the input image by observing their shadows. It is notable that the network learned this behavior from binary image-level labels alone (such as hazard stop = True/False):

Our initial results are promising. Nevertheless, our work is just the first step on a long journey towards learning robust driving models and transferring learned skills from simulation to the real world. We hope that our research will help establishing a new wave of learning-based self-driving methods which do not rely on hand-crafted pipelines and better adapt to the complexities of urban environments.
Further Information
To learn more about our work, check out the video here:
Here is a more detailed explanation recorded at the Conference on Robotic Learning (CoRL):
You can find more information (including the paper and supplementary) on the project page (including the research paper and the code). We are also open sourcing our dataset, so you are able to train your own agent and try to conquer the benchmark!
@inproceedings{Sauer2018CORL,
title = {Conditional Affordance Learning for Driving in Urban Environments},
author = {Axel Sauer and Nikolay Savinov and Andreas Geiger},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2019}
}
Acknowledgments
This research is a result of a collaboration between ETH Zurich and Max Planck Institute for Intelligent Systems. The core team includes Axel Sauer, Nikolay Savinov and Andreas Geiger. We also wish to thank Vanessa Diedrichs for many helpful discussions about autonomous driving and data visualization, and for her general support.



