
Robust Driving Across Diverse Weather Conditions in Urban Environments
Autonomous driving research has been gaining traction in industry and academia with the advancement in deep learning, availability of realistic simulators (CARLA, NVIDIA DRIVE) and large scale datasets (Argoverse, Waymo Open, Berkeley DeepDrive, nuScenes, Lyft Level 5, Cityscapes). While there has been considerable success in driving in empty scenarios or on highways, driving in urban cities introduces new challenges due to the presence of dense traffic, pedestrians and traffic conditions such as red lights, speed limits and stop signs. Moreover, a self-driving vehicle needs to be robust to diverse environments and weather conditions so that it can drive realiably across a wide range of visual scenarios. This forms the core research problem that we investigate in our recent work Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving - How to train a self-driving vehicle to drive reliably in diverse environmental conditions?.

Self-driving technology comprises of three components - perception, planning and control. Perception involves reasoning about the surrounding environment through the use of sensors (like camera and LIDAR), planning involves using the perceived knowledge to determine the trajectory (waypoints) that the vehicle needs to follow and control involves vehicle actuation (steering, throttle and brake signals). Over the past several years, there have been two major paradigms in self-driving research - modular approaches that contain dedicated modules for each component, and end-to-end trainable systems that directly learn a mapping from raw observations to vehicle controls. In our work, we focus on the latter (in particular, imitation learning) since it allows us to leverage the most recent advancements in deep learning.
Imitation Learning for Autonomous Driving
Imitation learning involves training a driving policy to mimic the actions of an expert driver (a policy is an agent that takes in observations of the environment and outputs vehicle controls). For this, a set of demonstrations is first collected by an expert (e.g. a human driver) in the real world or a simulated environment and then used to train the driving policy. In our work, we consider camera-based end-to-end driving in a simulated environment (CARLA) in which the driving agent gets the front camera image, current speed and high level navigational commands (turn left, turn right, go straight, follow lane) as inputs and predicts the steering, throttle and brake of the vehicle.
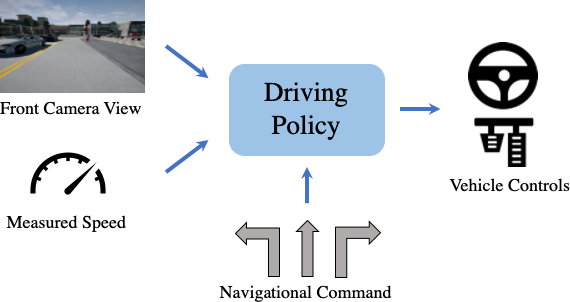
A primary challenge in imitation learning is that if the driving agent encounters a scenario which was not present in the expert demonstrations used to train that agent, then it does not know how to react, which may lead to collisions. For example, in the following video, we observe that the agent is not able to avoid collisions with the pedestrian or vehicle when it comes into close proximity. This happens because the scenarios involving close proximity to other pedestrians and vehicles are not present in the expert demonstrations since the expert drives very cautiously and stops well ahead of other agents. This phenomenon, in which the agent encounters different types of scenarios at test time as compared to expert demonstrations used for training, is referred to as covariate shift. Next, we describe a common technique called DAgger to address this problem.

Limitations of DAgger in Urban Scenarios
DAgger involves collecting demonstrations from the driving policy in addition to the expert. In this, we first train the policy using expert data, then let the learned policy drive in the environment, collect additional data (referred to as on-policy data) and add it to the training dataset and repeat the process again. In this way, we are able to collect different types of scenarios that the policy may encounter.
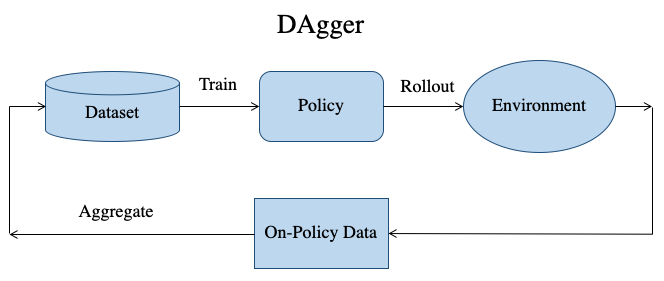
However, one important aspect to note here is that driving datasets have inherent bias. To understand this better, consider a human driving a car in a city. Most of the time, the car will be driving straight on a road and difficult scenarios involving intersections, turnings and traffic lights will be seldom encountered since they are relatively scarce compared to a straight portion of a road. Therefore, as on-policy data is added in DAgger, it is quite likely that the policy will only properly learn how to drive straight on a road. This problem is further exacerbated if the driving environment changes (city layout or weather conditions change). This issue is referred to as overfitting to the training conditions. In our work, we address these challenges and propose modifications to the DAgger algorithm for improved urban driving.
Our Approach
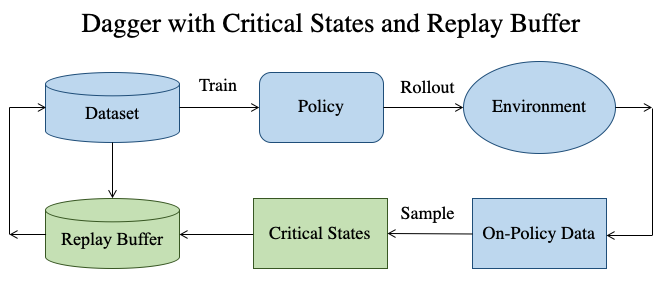
The two key ideas behind our approach are:
- To sample critical states from the collected on-policy data based on the utility they provide to the learned policy in terms of driving behavior.
- To incorporate a replay buffer mechanism which progressively focuses on the high uncertainty regions of the learned policy’s state distribution.
Intuitively, it makes sense to have difficult scenarios (e.g. interesections, turnings, close proximity to pedestrians & vehicles) represented in the training data. We refer to these scenarios as critical states since they are important for safe driving. Also, as explained earlier, the proportion of different types of scenarios matter a lot for the policy to learn different maneuvers. Therefore, we incorporate a replay buffer which helps to focus on difficult regions of the state distribution (wide spectrum of different scenarios encountered by the agent).
Results
We conduct extensive experiments on the CARLA NoCrash benchmark, focusing on the most challenging driving scenarios with dense pedestrian and vehicle traffic across a wide range of weather conditions. We observe that our approach enables the policy to drive well in diverse conditions and leads to significant reductions in collisions.

Further Information
To learn more about work, watch our video:
You can find more information (including the paper and supplementary) on our project page. If you are interested in experimenting further, check out our source code. We are happy to receive your feedback!
@inproceedings{Prakash2020CVPR,
title = {Exploring Data Aggregation in Policy Learning for Vision-based Urban Autonomous Driving},
author = {Prakash, Aditya and Behl, Aseem and Ohn-Bar, Eshed and Chitta, Kashyap and Geiger, Andreas},
booktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}



