
Single Image Motion Deblurring
Introduction
Motion blur is one of the most common factors de-grading image quality. It often arises when the image content changes quickly (e.g., due to fast camera motion) or when the environment is poorly illuminated, hence necessitating longer exposure times. Combining both situations, e.g., when self-driving car drives at dusk, further aggravates the problem.
Inverting the image degradation process and recovering a sharp image from one or multiple blurry images is called “image deblurring”. As many computer vision algorithms, including semantic segmentation, object detection and visual odometry, rely on visual input, blurry images challenge the performance of these algorithms. Image deblurring has thus received considerable attention.

Existing approaches
Existing approaches can be classified into classic optimization-based approaches or deep-learning-based approaches. Optimization-based approaches formulate the deblurring problem as an energy minimization problem. While they generalize well, classic approaches are usually computational intensive. Furthermore, they must rely on strong priors for the challenging and ill-posed single image motion deblurring problem, and thus typically do not work well if the assumptions do not hold. More recent deep-learning-based approaches formulate the problem as an image-to-image translational problem and achieve state-of-the-art performance in terms of both accuracy and efficiency. However, they often fail in scenarios for which the ground truth training data is difficult to acquire.
What do we do?
In this work, we propose a self-supervised model for motion deblurring. Instead of learning deblurring from paired blurry and sharp image pairs, our method explicitly takes into account the image formation process (i.e., how a blurry image is generated) to learn motion deblurring from blurry inputs alone. Towards this goal, we combine the advantages of both classic approaches and deep-learning-based approaches to solve the challenging image deblurring problem. In particular, we consider the blind image deblurring problem with spatially varying blur kernels. This is the most generic setup in which no prior information about the blur kernel is assumed to be known.
How do we do it?
We formulate deblurring as an inverse rendering problem, taking into account the physical image formation process: we first predict two deblurred images from which we estimate the corresponding optical flow. Using these predictions, we re-render the blurred images and minimize the difference with respect to the original blurry inputs.
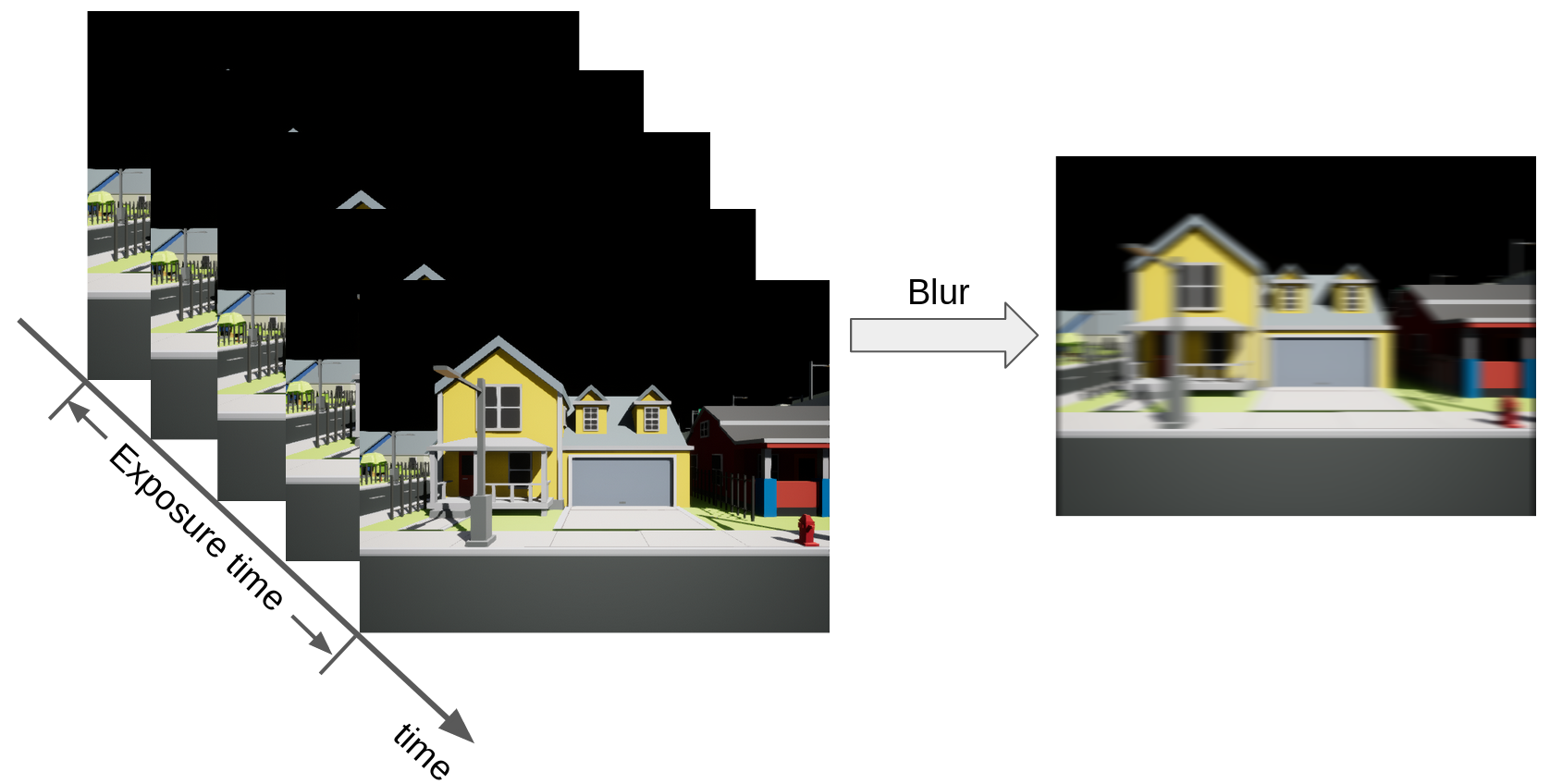
Does it work?
Our method achieves performance on par with state-of-the-art supervised approaches, which require blurry and sharp image pairs captured at the same point in time. The following videos demonstrate the results of our method.

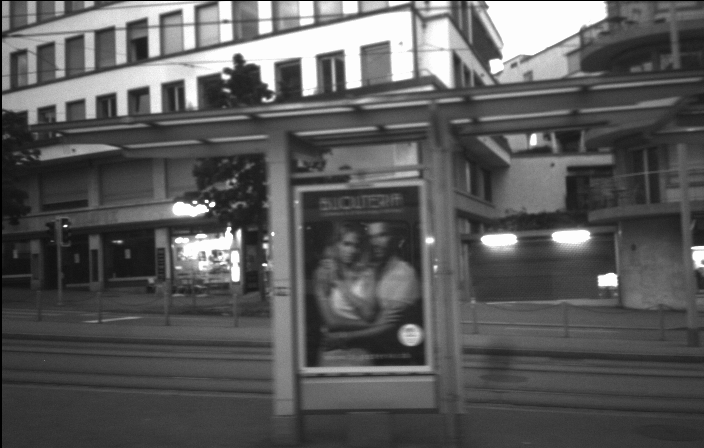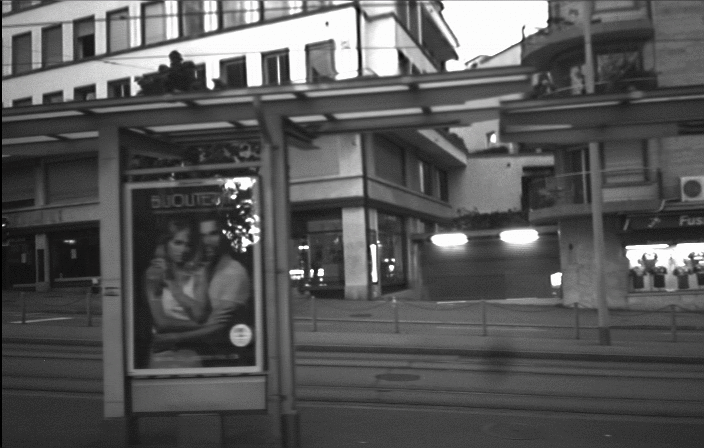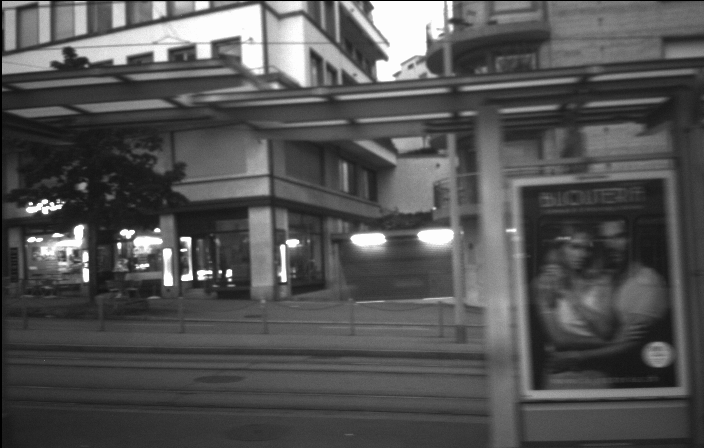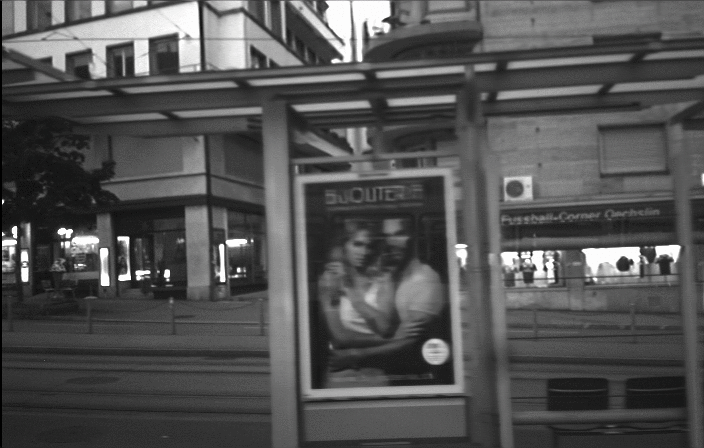
Further Information
Our paper is accepted to the Robotics and Automation Letters (RA-L) and will be presented at ICRA, 2020. For further information, please check out our paper on arXiv. Both our code and datasets are available on github.
BibTex
@article{Liu2020RAL,
author = {Peidong Liu and Joel Janai and Marc Pollefeys and Torsten Sattler and Andreas Geiger},
title = {Self-Supervised Linear Motion Deblurring},
journal = {Robotics and Automation Letters},
year = {2020}}



