
SMD-Nets: Stereo Mixture Density Networks
Introduction
Stereo matching indicates the problem of finding dense correspondences in pairs of images in order to perform 3D reconstruction. Recently, deep learning based stereo matching approaches are taking over, becoming one of the best performing methods as witnessed by the leaderboard across different datasets. However, although the performance of CNN-based algorithms has gained great improvement, some difficult problems still exists in the disparity estimation task, in particular:
- Over-smoothing effects at edge boundaries, causing bleeding artifacts in 3D point clouds
- Disparity estimates at pixel locations of a fixed resolution image grid
In the following figure, we illustrate the boundary bleeding problem that characterizes classical deep stereo networks (for clarity we visualize the disparity for a single image row):
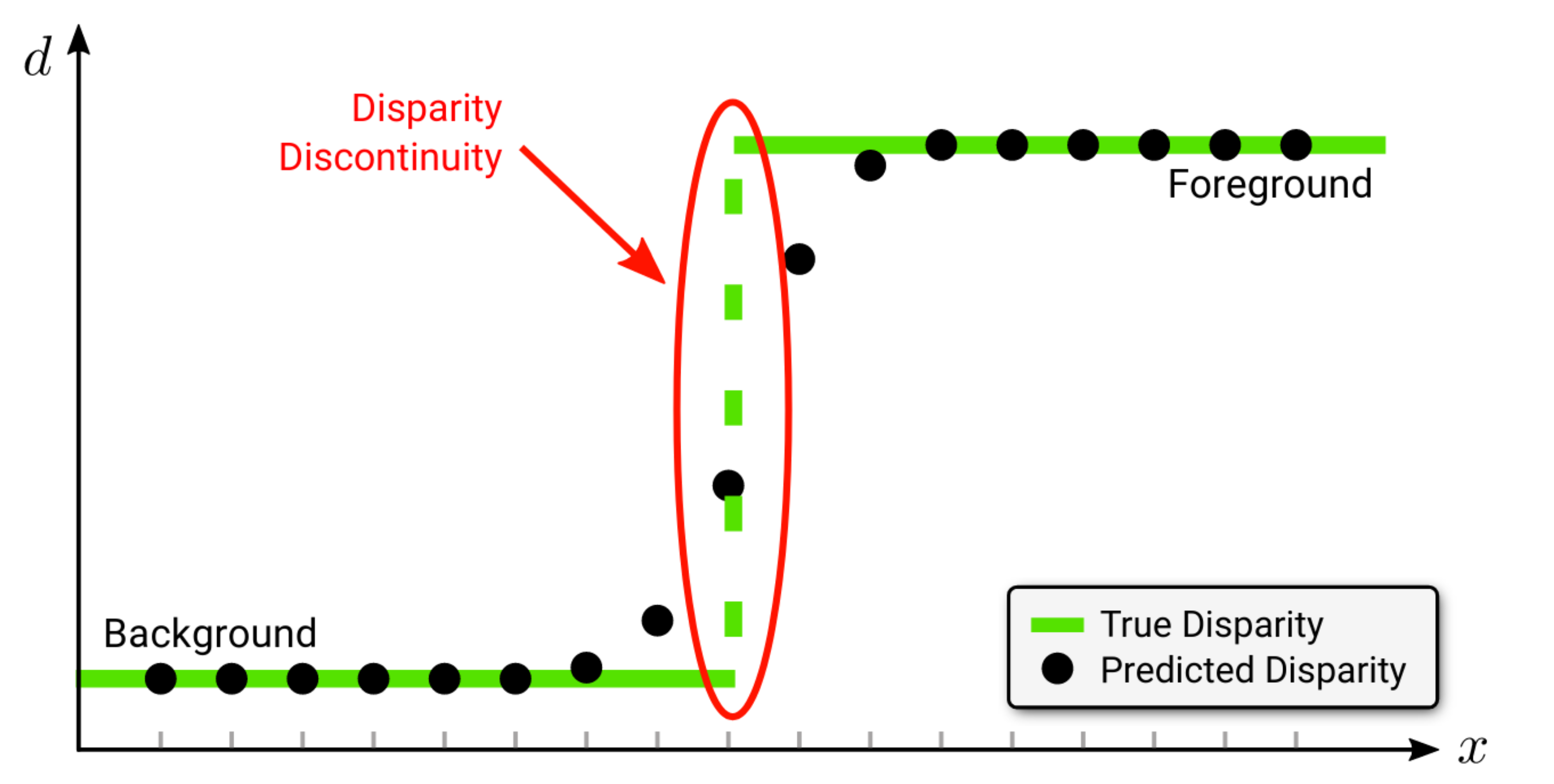
We can notice how standard networks for stereo regression predict disparity values at discrete spatial locations and continuously interpolate object boundaries. This effect, which can be observed in the figure below, causes artifacts (i.e. flying pixels) when disparities are converted to point clouds that could be potentially detrimental to subsequent applications such as 3D object detection.

Our Approach
How can we solve the over-smoothing problem? Our key idea in this project is to alter the output representation adopting a bimodal mixture distribution such that sharp discontinuities can be regressed despite the fact that the underlying neural networks are only able to make smooth predictions. We can visualize this as follows:
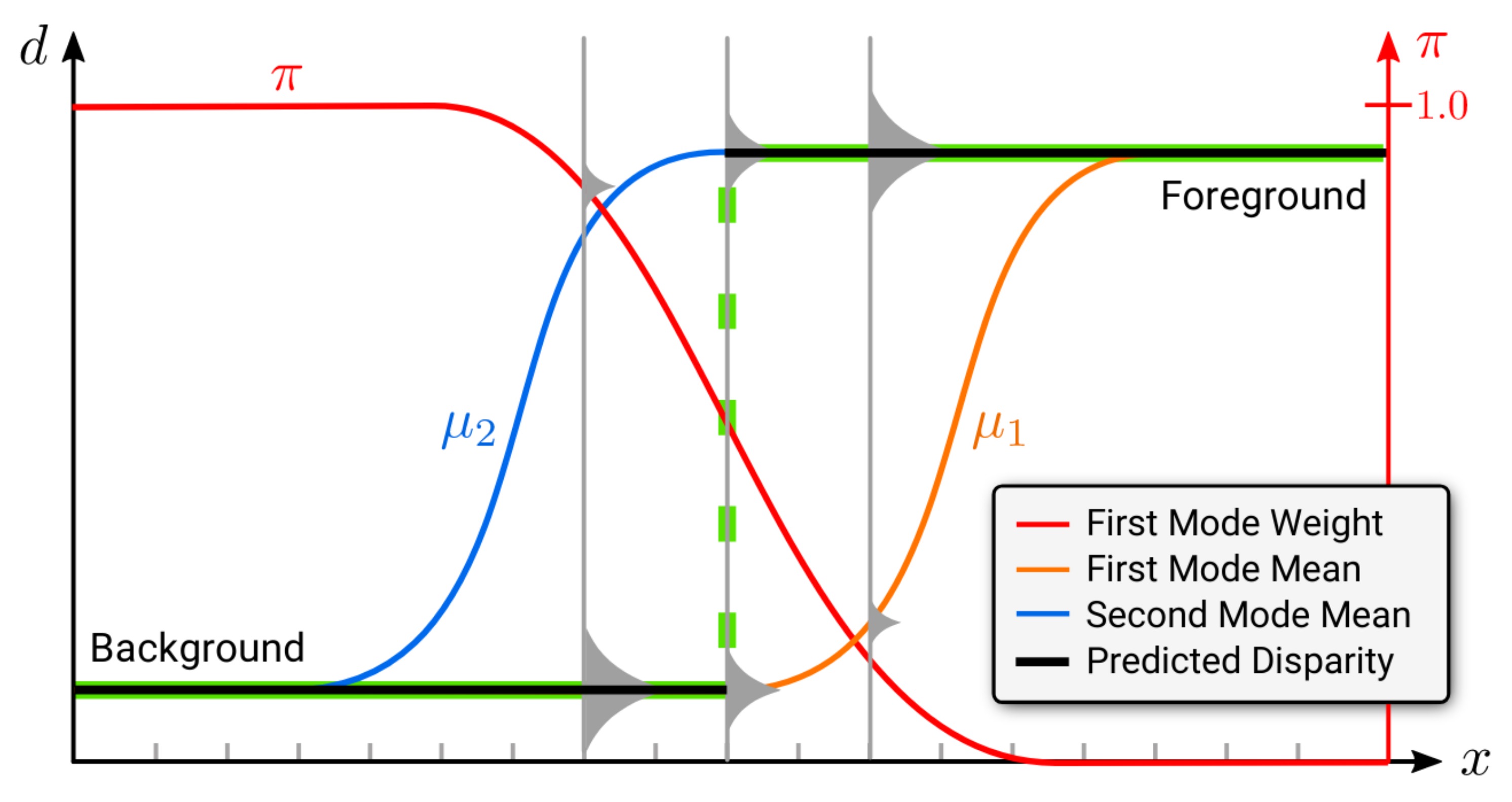
In this example, the first mode models the background while the second mode
models the foreground disparity close to the discontinuity. When the probability density (illustrated in gray) of the foreground mode becomes larger than the probability density of the background mode, the most likely disparity sharply transitions from the background to the foreground.

With this simple idea, we are able to produce sharp and accurate depth discontinuities and, thus, notably alleviate bleeding artifacts near object boundaries!
How can we estimate disparities at any continuous spatial location? Also in this case, the solution is straightforward. For every continuous 2D location of the image domain, we bilinearly interpolate the features computed by a standard stereo network and employ a multi-layer perceptron to map the abstract feature representation to the parameters of our bimodal mixture distribution. This strategy allows us to predict disparity maps at arbitrary spatial resolution!

Is this method designed for a specific stereo network? No, it isn’t. Our framework is compatible with a wide class of 2D and 3D stereo architectures existing in the literature. Moreover, it can be effectively adopted for other exciting tasks such as monocular depth estimation and active depth!
Stereo Super-Resolution
Our continuous formulation allows us to exploit ground truth at higher resolution than the input, which we refer to as stereo super resolution.

Here, a comparison of our model that estimates disparities at 128Mpx (top) and a standard stereo network that predicts disparity maps at 0.5Mpx resolution (bottom), both taking stereo pairs at 0.5 Mpx as input.
UnrealStereo4K
Motivated by the lack of large-scale, realistic and high-resolution stereo datasets, we introduce a new large-scale synthetic binocular stereo dataset with ground truth disparities at 3840×2160 resolution, comprising photo-realistic renderings of indoor and outdoor environments.

Results
Some qualitative results of the proposed SMD-Nets using PSMNet as stereo backbone. From left to right, the input image from the UnrealStereo4K test set, the predicted disparity and the corresponding error map.

Further Information
To learn more about work, check our video:
You can find more information (including the paper and supplementary) on our project page.
If you are interested in experimenting with our approach yourself, you can clone the source code of our project page and train your own models.
@INPROCEEDINGS{Tosi2021CVPR,
author = {Fabio Tosi and Yiyi Liao and Carolin Schmitt and Andreas Geiger},
title = {SMD-Nets: Stereo Mixture Density Networks},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}



